OpenAI模型常用参数详解
1. max_tokens(最大token数)
定义:指令生成的回答中包含的最大token数。例如,如果设置为100,那么模型生成的回答中token数不会超过100个。
用法:用来控制生成内容的长度。特别是在需要简短回答或有限字数情况下,这个参数非常实用。
例子:
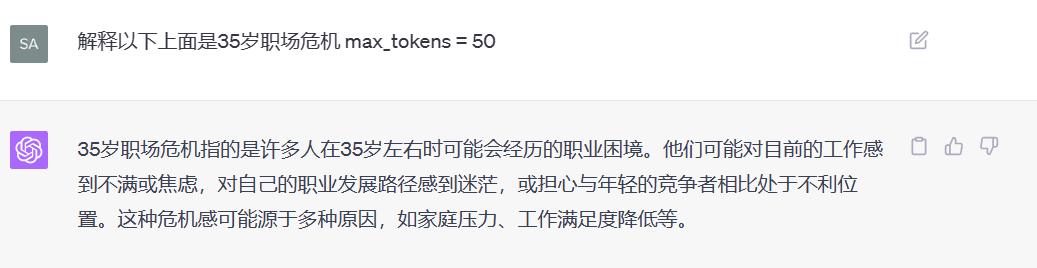
输入:你问模型一个问题:“请简单解释一下黑洞。”
max_tokens = 50:模型会尽量在50个token内完成回答。
- 回应:“黑洞是一个宇宙中极高密度的区域,其引力强大到光也无法逃脱。它是由大质量恒星坍缩形成的。”
2. temperature(温度/文风的温度)
定义:控制文本生成的随机性。值范围通常在0到1之间。值越大,生成文本越随机;值越小,生成文本越确定。
用法:用来调整模型回答的创造性。高温度适合创造性任务;低温度适合需要确定性高的回答。
例子:
输入:你要写一首关于秋天的诗。
temperature = 0.2(低温度,收敛回答):
- 回应:“秋天的树叶飘舞在风中,金黄色的田野映入眼帘。”
temperature = 0.8(高温度,更随机):
- 回应:“秋天的旋律在微风中回荡,金黄的梦幻洒满田野。”
使用较低温度生成的文本将更加集中和保守,而使用较高温度生成的文本则会更具创意和变化。温度的范围是从 0 到 1。
温度 = 0:模型会产生最确定的输出,但可能显得重复或模板化。
0 < 温度 < 0.5:输出将倾向于较为稳定和保守,提供高度相关且一致的回应。
温度 = 0.5:产生的文本会有一个适中的平衡,既不过于随机也不过于保守。
0.5 < 温度 < 1:输出会更具创意和变化,但可能牺牲一些连贯性。
温度 = 1:模型会产生最大程度的创意和随机性,可能产生出奇不意的答案,但风险也更高。

3. n(生成次数)
定义:模型对每个输入生成的回答数量。设置为n就会生成n个独立的回答。
用法:用来获取多个回答,便于选择或综合。
例子:
输入:你问模型一个问题:“什么是人工智能?”
n = 3:模型生成三个独立的回答。
回应1:“人工智能是模拟人类智能的计算机技术。”
回应2:“人工智能通过算法和大数据实现自动化任务。”
回应3:“人工智能涉及机器学习和神经网络等技术。”
4. top_p(控制采样)
定义:确定生成文本时考虑的token累计概率。值为0到1之间,常用来替代温度设置。top_p为0.9时,模型仅在最有可能的token集合(累计概率达到0.9)中进行选择。
用法:控制生成内容的多样性,top_p越小,生成内容越确定。
例子:
输入:描述一个梦想中的度假胜地。
top_p = 0.9(较有创意):
- 回应:“岛屿被蓝色的海水环绕,白色沙滩上点缀着茅草屋,椰子树随风摇曳。”
top_p = 0.5(较确定):
- 回应:“度假胜地是一座热带岛屿,有着美丽的海滩和清澈的海水,适合享受安静的时光。”
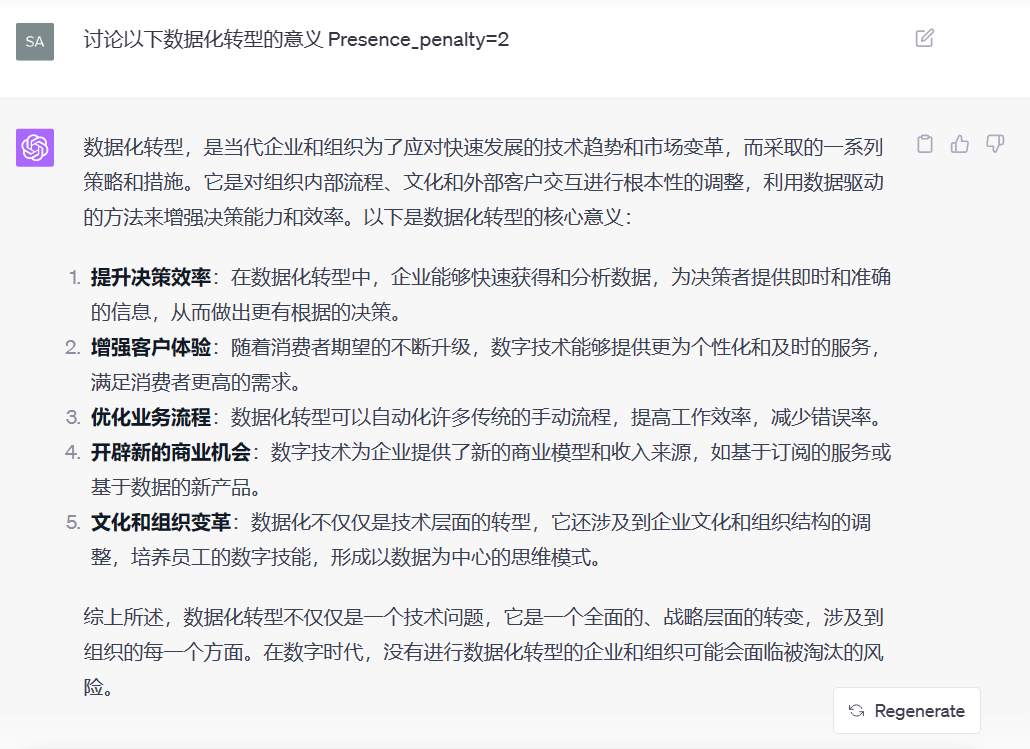
5. presence_penalty(出现惩罚/阻止调整)
定义:影响模型生成新主题内容的倾向。值范围通常在-2.0到2.0之间。较高的值鼓励模型生成前面未出现过的新内容。
用法:用来避免重复内容,增加多样性。
例子:
输入:重新生成描述夏天的句子。
presence_penalty = 1.0(较高惩罚):
- 回应:“夏天阳光充足,清凉的冰淇淋是人们的最爱。”
presence_penalty = 0.0(无惩罚):
- 回应:“夏天阳光灿烂,人们喜欢躺在沙滩上享受日光浴。”

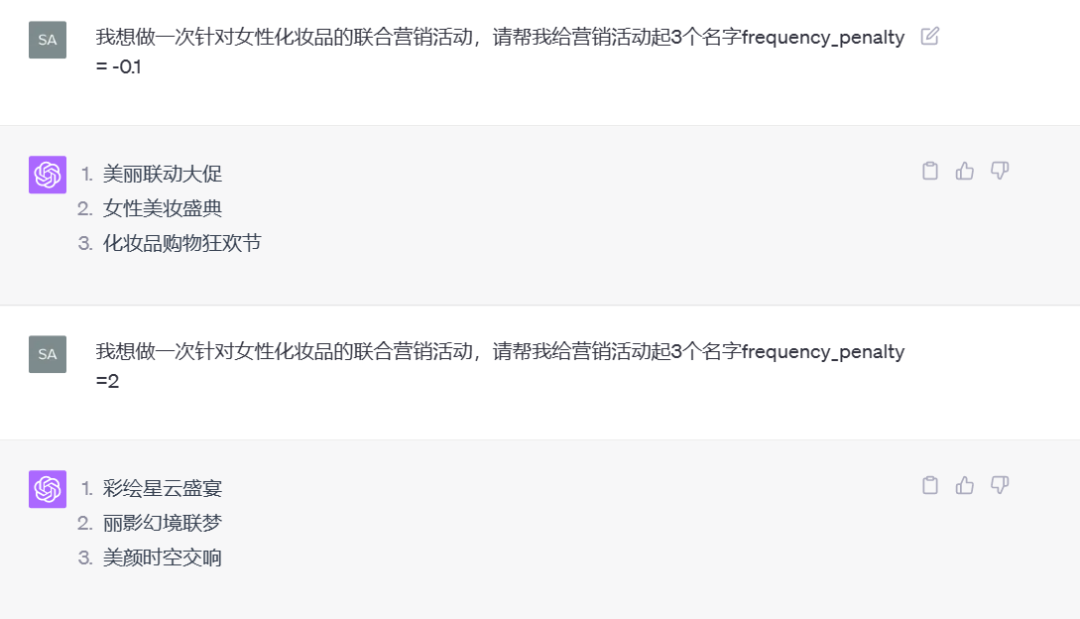
6. frequency_penalty(频率惩罚、短语效应)
定义:影响模型是否重复使用某些词或短语。值范围通常在-2.0到2.0之间。较高的值会减少模型重复使用某些词或短语的频率。
用法:用来减少重复词语,提高输出的流畅度和多样性。
例子:
输入:描述你的一天。
frequency_penalty = 1.5(较高惩罚):
- 回应:“我的一天开始于晨跑,然后享用早餐并开始工作。午餐后,进行一些锻炼和阅读。”
frequency_penalty = 0.0(无惩罚):
- 回应:“我的一天从晨跑开始,之后吃早餐准备工作。午饭后,我会去健身房锻炼,结束后读书放松。”
7. stream
定义:stream 参数用于控制是否以流式方式接收生成的文本。流式输出意味着生成的文本会逐步发送,而不是一次性全部发送。
用法:
stream=True:启用流式输出,生成的文本会逐步发送。stream=False:禁用流式输出,生成的文本会一次性发送。
例子:
如果你想要在用户输入问题后,逐字逐句地看到回答,可以设置
stream=True。如果你想要在用户输入问题后,等待一段时间再一次性看到完整回答,可以设置
stream=False。
总结
max_tokens:控制生成内容的长度。temperature:控制生成内容的随机性和创造性。n:生成多个回答供选择。top_p:通过概率控制生成内容的多样性。presence_penalty:鼓励生成新内容,避免重复。frequency_penalty:减少词语重复,提高多样性。stream:控制生成的文本是否以流式方式逐步发送。
理解这些参数可以帮助你更有效地定制和使用ChatGPT以满足各种需求。
实战中可以多个组合使用,比如
temperature:0.7 至 1,以获得最大的创意和多样性。
frequency_penalty:1 至 2,用于产生各种独特的短语和想法。
max_tokens:根据你所需的故事长度或场景进行设置。
OpenAI 接口文档
官方文档:https://platform.openai.com/docs/api-reference/chat/create
Apifox中文文档:https://openai.apifox.cn/
OpenAI 模型定价
模型定价:https://openai.com/api/pricing/
基本概念
Tokens(标记):
定义:在自然语言处理中,token是输入文本被分割成的小单元。一个token可以是一个单词、一个子词,甚至是一个字符。这取决于文本的具体分割方式。
举例:在GPT模型中,”Hello, world!” 可能被分割成几个token,比如 [‘Hello’, ‘,’, ‘ world’, ‘!’]。
计费方式:
单位:计费是按百万个输入token(1M input tokens)来计算的,即每处理一百万个输入token的费用为5美金。
实际意义:这意味着你使用GPT-4生成的文本越多,处理的输入token数量越大,费用也会随之增加。
示例和详细解释
示例一:简单对话
假设你使用GPT-4o进行一个简单对话,输入如下:
用户输入: “What is the capital of France?”
- Token 数量:这句话大概会被分成7个token。
总共6个token。
模型生成的输出: “The capital of France is Paris.”
- Token 数量:这句话大概会被分成7个token。
总共7个token。
整个对话会消耗13个token(6个输入 + 7个输出)。
理解和应用场景
成本控制:
优化使用:如果你对使用成本敏感,可以通过优化输入文本的长度和复杂度来控制费用。
批量处理:对于需要处理大量文本的应用,可以进行成本效益分析,确定最佳的使用策略。
商业应用:
对话系统:在客户服务、技术支持等应用中,可以根据对话量估算成本。
内容生成:对于需要生成大量内容的应用(如文章写作或编程助手),可以根据每百万个token的费用来预算项目成本。
总结
“US$5.00/1M input tokens”在GPT-4o中表示按百万个输入token来计费,每百万个输入token的计算费用为5美元。这种计费方式让用户能够更透明地了解和管理使用这些高级自然语言处理模型的成本。通过理解token的分割方式和具体的使用范例,用户可以更有效地计划和控制使用成本。GPT-4 可能提供两种不同的定价模式,分别为标准定价和批量API(Batch API)定价。让我们详细解释这些定价模式及其区别,以及为什么价格不同。
OpenAI 标准定价 vs 批量API
模型定价:https://openai.com/api/pricing/
Batch API:https://platform.openai.com/docs/guides/batch
标准定价 vs 批量API定价
标准定价(US$5.00/1M input tokens):
价格:每处理一百万个输入token的费用是5美元。
适用场景:这种定价通常适用于常规使用,比如单次请求或小规模的交互。这适用于大多数开发者和小型应用。
批量API定价(Batch API Pricing - US$2.50/1M input tokens):
价格:每处理一百万个输入token的费用是2.5美元,相当于标准定价的一半。
适用场景:这种较低价格通常适用于大量处理或批量操作场景。大型企业、需要处理大量数据的应用或者需要高频调用的场景更适合这种模式。
为什么价格不一样?
经济规模效应:
批量折扣:批量API定价反映了经济规模效应,即大量使用云计算资源可以分摊固定成本。因此,服务提供商通过较低的批量价格吸引大客户,用户通过批量使用享受折扣。
资源利用优化:批量请求可以优化资源分配,使提供商能更高效地利用计算资源,从而降低整体成本。
使用模式不同:
标准请求:标准定价适用于散布在较长时间内的单次请求或小规模的互动场景,这些场景下的调用可能更分散,资源利用率较低,需要更高的单价以覆盖运营和支持成本。
批量请求:批量API允许在短时间内处理大量请求,提升了资源利用率,同时减少了单次请求的管理和通信开销。这使服务提供商可以通过降低单价来吸引更多批量用户。
选择的考虑因素
使用量:
小规模:对于不频繁或小规模调用的开发者,标准定价可能更加适合,因为他们不会达到批量使用的门槛。
大规模:对于频繁调用或大规模数据处理的场景,批量API定价更加经济实惠。
预算和成本控制:
成本敏感:如果你的项目预算紧张,选择批量API可以显著降低成本。
方便性:标准定价可能提供更灵活的调用方式,并且不需要批量请求的规划。
技术实现:
批量处理:需要考虑如何将调用合并成批量请求,这可能需要一些额外的开发工作。
实时性:标准定价可能更适合需要实时响应的应用,而批量处理适用于可以延迟处理的任务。
总结
两个不同的定价方案主要区别在于使用模式和规模的不同。标准定价(US5.00/1������������)适用于小规模和分散调用,而批量���定价(��2.50/1M input tokens)更适合大规模、批量处理的场景。价格差异反映了经济规模效应和资源利用的优化,当选择哪种定价方式时,需要根据具体的使用场景和需求进行考虑。