一、Vector stores(向量存储)
存储和搜索非结构化数据的最常见方法之一是将其嵌入并存储生成的嵌入向量, 然后在查询时将非结构化查询嵌入并检索与嵌入查询“最相似”的嵌入向量。 向量存储会处理存储嵌入数据并为您执行向量搜索。 可以通过以下方式将向量存储转换为检索器接口:
Retrievers(检索器)是一个接口,根据非结构化查询返回文档。 它比向量存储更通用。 检索器不需要能够存储文档,只需要能够返回(或检索)它们。 检索器可以从向量存储器创建,但也足够广泛,包括 Wikipedia 搜索和 Amazon Kendra。 检索器接受字符串查询作为输入,并返回文档列表作为输出。
1 | vectorstore = MyVectorStore() |
二、向量嵌入
向量嵌入(Vector Embeddings),对于传统数据库,搜索功能都是基于不同的索引方式(B Tree、倒排索引等)加上精确匹配和排序算法(BM25、TF-IDF)等实现的。本质还是基于文本的精确匹配,这种索引和搜索算法对于关键字的搜索功能非常合适,但对于语义搜索功能就非常弱。
例如,如果你搜索 “小狗”,那么你只能得到带有“小狗” 关键字相关的结果,而无法得到 “柯基”、“金毛” 等结果,因为 “小狗” 和“金毛”是不同的词,传统数据库无法识别它们的语义关系,所以传统的应用需要人为的将 “小狗” 和“金毛”等词之间打上特征标签进行关联,这样才能实现语义搜索。而如何将生成和挑选特征这个过程,也被称为 Feature Engineering(特征工程),它是将原始数据转化成更好的表达问题本质的特征的过程。
但是如果你需要处理非结构化的数据,就会发现非结构化数据的特征数量会开始快速膨胀,例如我们处理的是图像、音频、视频等数据,这个过程就变得非常困难。例如,对于图像,可以标注颜色、形状、纹理、边缘、对象、场景等特征,但是这些特征太多了,而且很难人为的进行标注,所以我们需要一种自动化的方式来提取这些特征,而这可以通过 Vector Embedding 实现。
Vector Embedding 是由 AI 模型(例如大型语言模型 LLM)生成的,它会根据不同的算法生成高维度的向量数据,代表着数据的不同特征,这些特征代表了数据的不同维度。例如,对于文本,这些特征可能包括词汇、语法、语义、情感、情绪、主题、上下文等。对于音频,这些特征可能包括音调、节奏、音高、音色、音量、语音、音乐等。
例如对于目前来说,文本向量可以通过 OpenAI 的 text-embedding-ada-002 模型生成,图像向量可以通过 clip-vit-base-patch32 模型生成,而音频向量可以通过 wav2vec2-base-960h 模型生成。这些向量都是通过 AI 模型生成的,所以它们都是具有语义信息的。
例如我们将这句话 “Your text string goes here” 用 text-embedding-ada-002 模型进行文本 Embedding,它会生成一个 1536 维的向量,得到的结果是这样:“-0.006929283495992422, -0.005336422007530928, ... -4547132266452536e-05,-0.024047505110502243”,它是一个长度为 1536 的数组。这个向量就包含了这句话的所有特征,这些特征包括词汇、语法,我们可以将它存入向量数据库中,以便我们后续进行语义搜索。
三、特征和向量
虽然向量数据库的核心在于相似性搜索 (Similarity Search),但在深入了解相似性搜索前,我们需要先详细了解一下特征和向量的概念和原理。
我们先思考一个问题?为什么我们在生活中区分不同的物品和事物?
如果从理论角度出发,这是因为我们会通过识别不同事物之间不同的特征来识别种类,例如分别不同种类的小狗,就可以通过体型大小、毛发长度、鼻子长短等特征来区分。如下面这张照片按照体型排序,可以看到体型越大的狗越靠近坐标轴右边,这样就能得到一个体型特征的一维坐标和对应的数值,从 0 到 1 的数字中得到每只狗在坐标系中的位置。
然而单靠一个体型大小的特征并不够,像照片中哈士奇、金毛和拉布拉多的体型就非常接近,我们无法区分。所以我们会继续观察其它的特征,例如毛发的长短。
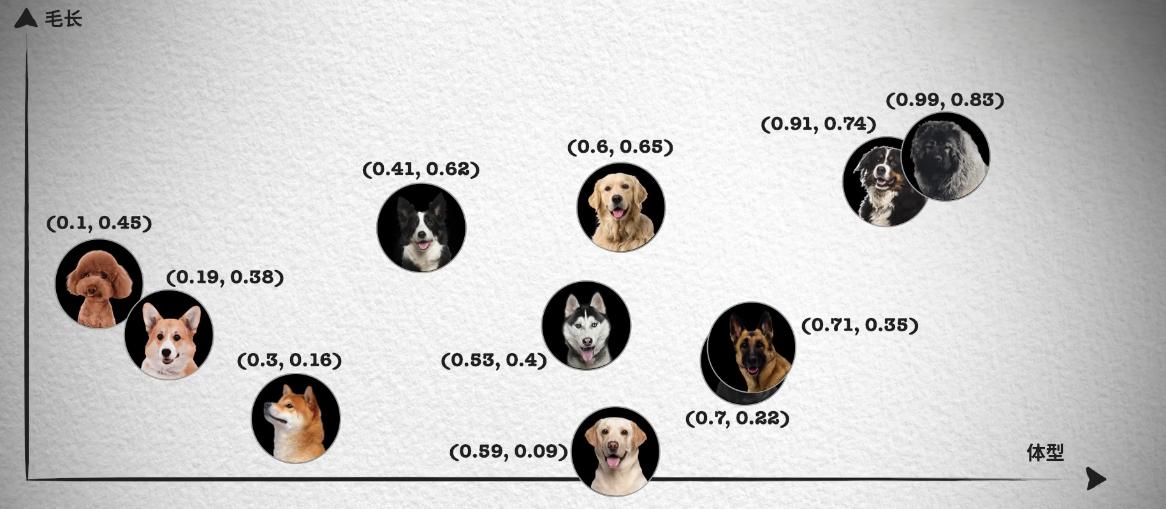
这样每只狗对应一个二维坐标点,我们就能轻易的将哈士奇、金毛和拉布拉多区分开来,如果这时仍然无法很好的区分德牧和罗威纳犬。我们就可以继续再从其它的特征区分,比如鼻子的长短,这样就能得到一个三维的坐标系和每只狗在三维坐标系中的位置。
在这种情况下,只要特征足够多,就能够将所有的狗区分开来,最后就能得到一个高维的坐标系,虽然我们想象不出高维坐标系长什么样,但是在数组中,我们只需要一直向数组中追加数字就可以了。
实际上,只要维度够多,我们就能够将所有的事物区分开来,世间万物都可以用一个多维坐标系来表示,它们都在一个高维的特征空间中对应着一个坐标点。
那这和相似性搜索 (Similarity Search) 有什么关系呢?你会发现在上面的二维坐标中,德牧和罗威纳犬的坐标就非常接近,这就意味着它们的特征也非常接近。我们都知道向量是具有大小和方向的数学结构,所以可以将这些特征用向量来表示,这样就能够通过计算向量之间的距离来判断它们的相似度,这就是相似性测量。
四、Chroma
官方文档:https://docs.trychroma.com/
Chroma ( /‘kromə/ n. (色彩的)浓度,色度 )是一个以人工智能为基础的开源向量数据库,专注于开发者的生产力和幸福感。Chroma 使用 Apache 2.0 许可证。 使用以下命令安装 Chroma:
1 | pip install langchain-chroma |
Chroma 可以以多种模式运行。以下是每种模式的示例,均与 LangChain 集成:
in-memory- 在 Python 脚本或 Jupyter 笔记本中in-memory with persistance- 在脚本或笔记本中保存/加载到磁盘in a docker container- 作为在本地机器或云中运行的服务器
与任何其他数据库一样,您可以进行以下操作:
.add.get.update.upsert.delete.peek而
.query则运行相似性搜索。
查看完整文档,请访问 docs。要直接访问这些方法,可以使用 ._collection.method()。
1. 基本示例
在这个基本示例中,我们获取《乔布斯演讲稿》,将其分割成片段,使用开源嵌入模型进行嵌入,加载到 Chroma 中,然后进行查询。
1 | # 示例:chroma_base.py |
1 | During the next five years, I started a company named NeXT, another company named Pixar, and fell in love with an amazing woman who would become my wife. Pixar went on to create the worlds first computer animated feature film, Toy Story, and is now the most successful animation studio in the world. In a remarkable turn of events, Apple bought NeXT, I retuned to Apple, and the technology we developed at NeXT is at the heart of Apple's current renaissance. And Laurene and I have a wonderful family together. |
2. 基本示例(包括保存到磁盘)
在上一个示例的基础上,如果您想要保存到磁盘,只需初始化 Chroma 客户端并传递要保存数据的目录。
注意:Chroma 尽最大努力自动将数据保存到磁盘,但多个内存客户端可能会相互干扰。最佳做法是,任何给定时间只运行一个客户端。
1 | # 示例:chroma_disk.py |
1 | During the next five years, I started a company named NeXT, another company named Pixar, and fell in love with an amazing woman who would become my wife. Pixar went on to create the worlds first computer animated feature film, Toy Story, and is now the most successful animation studio in the world. In a remarkable turn of events, Apple bought NeXT, I retuned to Apple, and the technology we developed at NeXT is at the heart of Apple's current renaissance. And Laurene and I have a wonderful family together. |
3. 将 Chroma 客户端传递给 Langchain
您还可以创建一个 Chroma 客户端并将其传递给 LangChain。如果您希望更轻松地访问底层数据库,这将特别有用。
您还可以指定要让 LangChain 使用的集合名称。
1 | # 示例:chroma_client.py |
1 | Insert of existing embedding ID: 1 |
4. 更新和删除
在构建真实应用程序时,您不仅希望添加数据,还希望更新和删除数据。
Chroma 要求用户提供 ids 来简化这里的簿记工作。ids 可以是文件名,也可以是类似 filename_paragraphNumber 的组合哈希值。
Chroma 支持所有这些操作,尽管有些操作仍在通过 LangChain 接口进行整合。额外的工作流改进将很快添加。
以下是一个基本示例,展示如何执行各种操作:
1 | # 示例:chroma_update.py |
1 | 更新前内容: |
5. 使用 OpenAI Embeddings
许多人喜欢使用 OpenAIEmbeddings,以下是如何设置它。
1 | # 示例:chroma_openai.py |
1 | During the next five years, I started a company named NeXT, another company named Pixar, and fell in love with an amazing woman who would become my wife. Pixar went on to create the worlds first computer animated feature film, Toy Story, and is now the most successful animation studio in the world. In a remarkable turn of events, Apple bought NeXT, I retuned to Apple, and the technology we developed at NeXT is at the heart of Apple's current renaissance. And Laurene and I have a wonderful family together. |
6. 其他功能
6.1 带分数的相似性搜索
返回的距离分数是余弦距离。因此,分数越高越好。
1 | # 示例:chroma_other.py |
1 | docs[0] |
1 | (Document(metadata={'source': '../../resource/knowledge.txt'}, page_content="During the next five years, I started a company named NeXT, another company named Pixar, and fell in love with an amazing woman who would become my wife. Pixar went on to create the worlds first computer animated feature film, Toy Story, and is now the most successful animation studio in the world. In a remarkable turn of events, Apple bought NeXT, I retuned to Apple, and the technology we developed at NeXT is at the heart of Apple's current renaissance. And Laurene and I have a wonderful family together.\n在接下来的五年里, 我创立了一个名叫 NeXT 的公司,还有一个叫Pixar的公司,然后和一个后来成为我妻子的优雅女人相识。Pixar 制作了世界上第一个用电脑制作的动画电影——“”玩具总动员”,Pixar 现在也是世界上最成功的电脑制作工作室。在后来的一系列运转中,Apple 收购了NeXT,然后我又回到了苹果公司。我们在NeXT 发展的技术在 Apple 的复兴之中发挥了关键的作用。我还和 Laurence 一起建立了一个幸福的家庭。"), 0.8513926863670349) |
6.2 检索器选项
本节介绍如何在检索器中使用 Chroma 的不同选项。
MMR:除了在检索器对象中使用相似性搜索外,还可以使用 MMR(Maximal Marginal Relevance,最大边际相关性)是一种信息检索和文本摘要技术,用于在选择文档或文本片段时平衡相关性和多样性。其主要目的是在检索结果中既包含与查询高度相关的内容,又避免结果之间的高度冗余。
MMR 的作用
提高结果的多样性:通过引入多样性,MMR 可以避免检索结果中出现重复信息,从而提供更全面的答案。
平衡相关性和新颖性:MMR 在选择结果时,既考虑与查询的相关性,也考虑新信息的引入,以确保结果的多样性和覆盖面。
减少冗余:通过避免选择与已选结果高度相似的文档,MMR 可以减少冗余,提高信息的利用效率。
在检索器对象中使用 MMR
在使用向量检索器(如 FAISS)时,通常通过相似性搜索来查找与查询最相关的文档。然而,这种方法有时可能会返回许多相似的结果,导致信息冗余。MMR 可以在这种情况下发挥作用,通过以下步骤实现:
计算相关性:首先,计算每个候选文档与查询的相似性得分。
计算多样性:然后,计算每个候选文档与已选文档集合的相似性得分。
选择文档:在每一步选择一个文档,使得该文档在相关性和多样性之间达到最佳平衡。
1 | # 示例:chroma_other.py |
1 | retriever.invoke(query)[0] |
1 | page_content='During the next five years, I started a company named NeXT, another company named Pixar, and fell in love with an amazing woman who would become my wife. Pixar went on to create the worlds first computer animated feature film, Toy Story, and is now the most successful animation studio in the world. In a remarkable turn of events, Apple bought NeXT, I retuned to Apple, and the technology we developed at NeXT is at the heart of Apple's current renaissance. And Laurene and I have a wonderful family together. |
五、Weaviate
如何使用 langchain-weaviate 包在 LangChain 中开始使用 Weaviate 向量存储。
Weaviate 是一个开源的向量数据库。它允许您存储来自您喜爱的机器学习模型的数据对象和向量嵌入,并能够无缝地扩展到数十亿个数据对象。
官方文档:https://weaviate.io/developers/weaviate
要使用此集成,您需要运行一个 Weaviate 数据库实例。
1. 最低版本
此模块需要 Weaviate 1.23.7 或更高版本。但是,我们建议您使用最新版本的 Weaviate。
2. 连接到 Weaviate
在本文中,我们假设您在 http://localhost:8080 上运行了一个本地的 Weaviate 实例,并且端口 50051 用于 gRPC 通信。因此,我们将使用以下代码连接到 Weaviate:
1 | weaviate_client = weaviate.connect_to_local() |
2.1 其他部署选项
Weaviate 可以以许多不同的方式进行部署,例如使用Weaviate Cloud Services (WCS)、Docker或Kubernetes。
如果您的 Weaviate 实例以其他方式部署,可以在此处阅读更多信息关于连接到 Weaviate 的不同方式。您可以使用不同的辅助函数,或者创建一个自定义实例。
请注意,您需要一个 v4 客户端 API,它将创建一个 weaviate.WeaviateClient 对象。
2.2 认证
一些 Weaviate 实例,例如在 WCS 上运行的实例,启用了认证,例如 API 密钥和/或用户名+密码认证。
3. 安装
1 | # 安装包 |
4. 环境设置
本文使用 OpenAIEmbeddings 通过 OpenAI API。我们建议获取一个 OpenAI API 密钥,并将其作为名为 OPENAI_API_KEY 的环境变量导出。
完成后,您的 OpenAI API 密钥将被自动读取。如果您对环境变量不熟悉,可以在此处或此指南中阅读更多关于它们的信息。
配置 Weaviate 的 WCD_DEMO_URL 和 WCD_DEMO_RO_KEY
1 | setx WCD_DEMO_URL "" |
5. 通过相似性查找对象
以下是一个示例,演示如何通过查询查找与之相似的对象,从数据导入到查询 Weaviate 实例。
步骤 1:数据导入
首先,我们将创建要添加到 Weaviate 的数据,方法是加载并分块长文本文件的内容。
1 | from langchain_community.document_loaders import TextLoader |
现在,我们可以导入数据。要这样做,连接到 Weaviate 实例,并使用生成的 weaviate_client 对象。例如,我们可以将文档导入如下所示:
1 | # 示例:weaviate_client.py |
步骤2:执行搜索
现在我们可以执行相似度搜索。这将返回与查询文本最相似的文档,基于存储在 Weaviate 中的嵌入和从查询文本生成的等效嵌入。
1 | # 示例:weaviate_search.py |
1 | During the next five years, I started a company named NeXT, another company named Pixar, and fell in love with an amazing woman who would become my wife. Pixar went on to create the worlds first computer animated feature film, Toy Story, and is now the most successful animation studio in the world. In a remarkable turn of events, Apple bought NeXT, I retuned to Apple, and the technology we developed at NeXT is at the heart of Apple's current renaissance. And Laurene and I have a wonderful family together. |
步骤3:量化结果相似性
您可以选择检索相关性“分数”。这是一个相对分数,表示特定搜索结果在搜索结果池中的好坏程度。
请注意,这是相对分数,意味着不应用于确定相关性的阈值。但是,它可用于比较整个搜索结果集中不同搜索结果的相关性。
1 | # 示例:weaviate_similarity.py |
1 | 0.700 : During the next five years, I started a company named NeXT, another company named Pixar, and fell in... |
六、Qdrant
1. Qdrant 介绍
Qdrant(quadrant /‘kwɑdrənt/ n. 象限;象限仪;四分之一圆)是一个向量相似度搜索引擎。它提供了一个生产就绪的服务,具有方便的 API 来存储、搜索和管理点 - 带有附加载荷的向量。Qdrant 专门支持扩展过滤功能,使其对各种神经网络或基于语义的匹配、分面搜索和其他应用非常有用。
官方文档:https://qdrant.tech/documentation/
以下展示了如何使用与 Qdrant 向量数据库相关的功能。
有各种运行 Qdrant 的模式,取决于所选择的模式,会有一些细微的差异。选项包括:
本地模式,无需服务器
Qdrant 云
请参阅安装说明。
1 | %pip install --upgrade --quiet langchain-qdrant langchain-openai langchain |
1 | # 示例:qdrant_local.py |
1 | loader = TextLoader("../../resource/knowledge.txt", encoding="UTF-8") |
2. 本地模式
Python 客户端允许您在本地模式下运行相同的代码,而无需运行 Qdrant 服务器。这对于测试和调试或者如果您计划仅存储少量向量非常有用。嵌入可能完全保存在内存中或者持久化在磁盘上。
2.1 内存中
对于一些测试场景和快速实验,您可能更喜欢仅将所有数据保存在内存中,因此当客户端被销毁时数据会丢失 - 通常在脚本/笔记本的末尾。
1 | #示例:qdrant_local.py |
2.2 磁盘存储
在不使用 Qdrant 服务器的本地模式下,还可以将您的向量存储在磁盘上,以便它们在运行之间持久化。
1 | #示例:qdrant_disk.py |
3. 相似度搜索
使用 Qdrant 向量存储的最简单场景是执行相似度搜索。在幕后,我们的查询将使用 embedding_function 对查询进行编码,并用于在 Qdrant 集合中查找相似的文档。
1 | query = "Pixar公司是做什么的?" |
1 | print(found_docs[0].page_content) |
1 | During the next five years, I started a company named NeXT, another company named Pixar, and fell in love with an amazing woman who would become my wife. Pixar went on to create the worlds first computer animated feature film, Toy Story, and is now the most successful animation studio in the world. In a remarkable turn of events, Apple bought NeXT, I retuned to Apple, and the technology we developed at NeXT is at the heart of Apple's current renaissance. And Laurene and I have a wonderful family together. |
4. Qdrant 云
如果您不想忙于管理基础设施,可以选择在 Qdrant 云上设置一个完全托管的 Qdrant 集群。包括一个永久免费的 1GB 集群供试用。使用托管版本与使用 Qdrant 的主要区别在于,您需要提供 API 密钥以防止公开访问您的部署。该值也可以设置在 QDRANT_API_KEY 环境变量中。
1 | url = "<---qdrant cloud cluster url here --->" |
七、Milvus
Milvus 介绍
Milvus 是一个数据库,用于存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大规模嵌入向量。
官方文档:https://milvus.io/docs/overview.md
下面讲解如何使用与 Milvus 向量数据库相关的功能。
配置环境变量 MILVUS_API_URL 和 MILVUS_API_KEY
1 | setx MILVUS_API_URL "" |
zilliz:https://cloud.zilliz.com/
要运行,您应该已经启动并运行了一个 Milvus 实例。
1 | # 示例:milvus_zilliz.py |
1 | vector_db = Zilliz.from_documents( # or Milvus.from_documents |
1 | query = "Pixar公司是做什么的?" |
1 | print(docs[0].page_content) |
1 | During the next five years, I started a company named NeXT, another company named Pixar, and fell in love with an amazing woman who would become my wife. Pixar went on to create the worlds first computer animated feature film, Toy Story, and is now the most successful animation studio in the world. In a remarkable turn of events, Apple bought NeXT, I retuned to Apple, and the technology we developed at NeXT is at the heart of Apple's current renaissance. And Laurene and I have a wonderful family together. |
八、总结
下面是 Chroma、Weaviate、Qdrant 和 Milvus 四个向量数据库的功能对比:
这些数据库在功能和特性上各有优势,选择合适的数据库应根据具体的应用需求和技术栈来决定。