一、导入依赖库 我们将首先导入聊天机器人所需的库。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import timefrom datetime import datetimeimport requestsimport streamlit as stimport wikipediafrom bs4 import BeautifulSoupfrom langchain.schema import AIMessage, HumanMessage, SystemMessagefrom langchain.text_splitter import CharacterTextSplitterfrom langchain_community.vectorstores import FAISSfrom langchain_openai import ChatOpenAIfrom langchain_openai import OpenAIEmbeddingsfrom streamlit_chat import messageglobal docsearchfrom langchain.globals import set_verbosedocsearch = None
二、爬取维基百科 构建聊天机器人的第一步是访问维基百科文章并提取内容。该 get_wiki 函数接受搜索词并返回整页内容和维基百科文章的摘要。该 wikipedia.summary 方法搜索摘要,以及 requests 用于访问文章的 URL 的模块。该 BeautifulSoup 模块使用在解析页面的 HTML 内容,该 content_div.find_all('p') 行从页面上的段落中提取文本。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 def get_wiki (search ): lang = "zh" """ 从维基百科获取摘要 """ wikipedia.set_lang(lang) summary = wikipedia.summary(search, sentences=5 ) """ 抓取所请求查询的维基百科页面 """ url = f"https://{lang} .wikipedia.org/wiki/{search} " response = requests.get(url) soup = BeautifulSoup(response.content, "html.parser" ) content_div = soup.find(id ="mw-content-text" ) paras = content_div.find_all('p' ) full_page_content = "" for para in paras: full_page_content += para.text return full_page_content, summary
三、设置用户界面 接下来,我们使用 Streamlit 设置用户界面。我们首先创建一个标题:
1 st.markdown("<h1 style='text-align: center; color: Black;'>基于 Web URL 的问答</h1>" , unsafe_allow_html=True )
这将为聊天机器人创建一个大而居中的标题。
环境变量配置好 OPENAI_BASE_URL 和 OPENAI_API_KEY
1 2 setx OPENAI_BASE_URL "https://api.openai.com/v1" setx OPENAI_API_KEY "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
一旦用户输入他们的 OpenAI 密钥,我们就会初始化 GPT 模型并要求他们输入搜索查询,该查询将用于抓取相关的 Wikipedia 页面。get_wiki()函数将返回搜索查询和抓取页面的摘要。现在,如果它返回了一些值,则 Q&A 字段将被激活,用户可以提问。
1 2 3 4 5 6 7 search = st.text_input("请输入要检索的关键词" ) if len (search): wiki_content, summary = get_wiki(search) if len (wiki_content):try : st.write(summary) user_query = st.text_input("You: " , "" , key="input" ) send_button = st.button("Send" )
现在,我们初始化FAISS向量数据库
1 2 3 4 5 6 7 8 9 10 def init_db (wiki_content ):print ("初始化FAISS向量数据库..." ) text_splitter = CharacterTextSplitter( separator="\n" , chunk_size=1000 , chunk_overlap=200 , length_function=len , ) texts = text_splitter.split_text(wiki_content) embeddings = OpenAIEmbeddings()global doc_search doc_search = FAISS.from_texts(texts, embeddings)
建立索引后,我们就可以查询用户的请求。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def get_bot_response (user_query ): docs = doc_search.similarity_search(user_query, K=6 ) main_content = user_query + "\n\n" for doc in docs: main_content += doc.page_content + "\n\n" messages.append(HumanMessage(content=main_content)) ai_response = chat.invoke(messages).content messages.pop() messages.append(HumanMessage(content=user_query)) messages.append(AIMessage(content=ai_response)) return ai_response
就这样!你就拥有了专属于您的友好机器人,它可以回答您关于维基百科文章的查询。
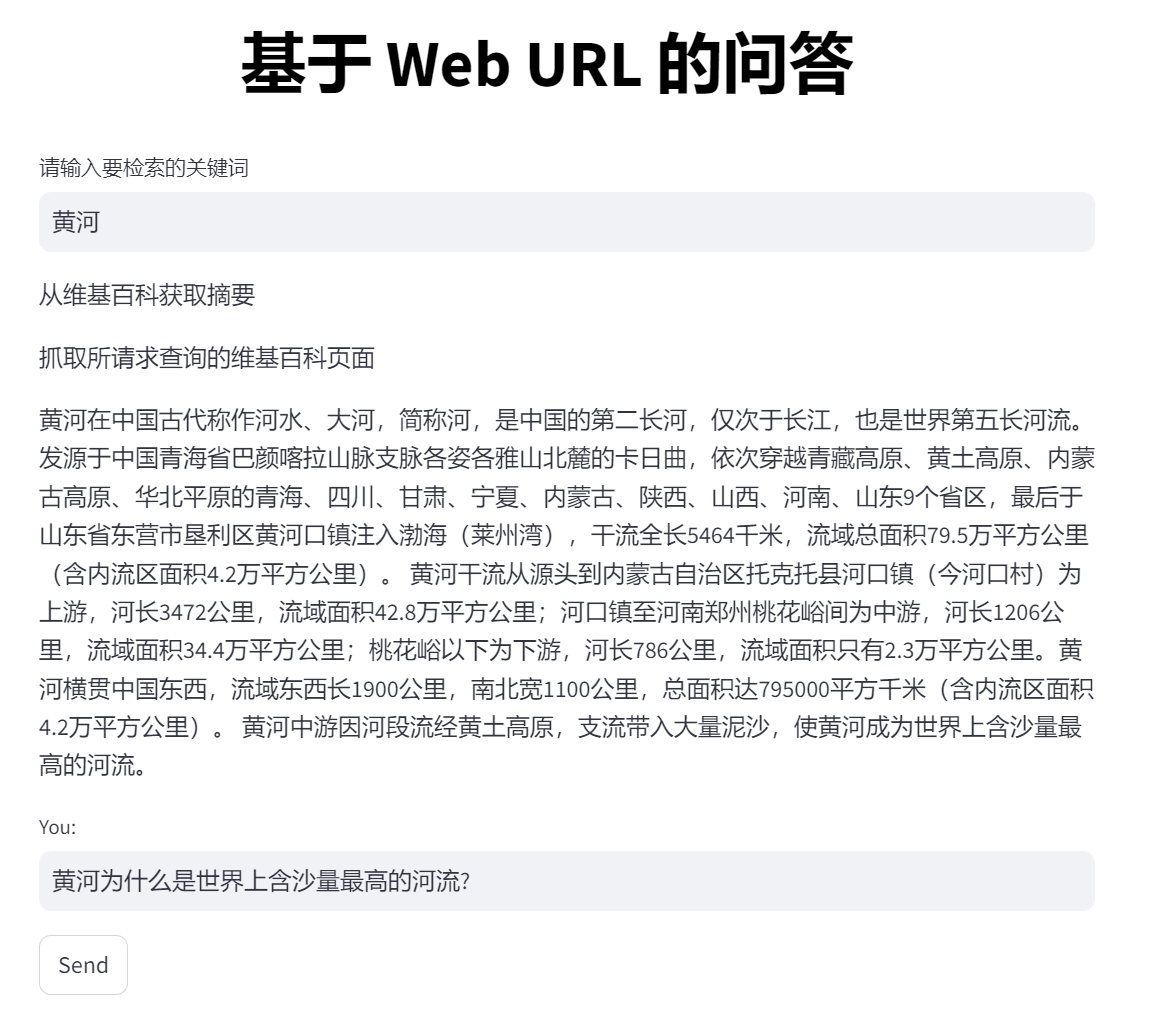
四、问答效果 问题1:黄河
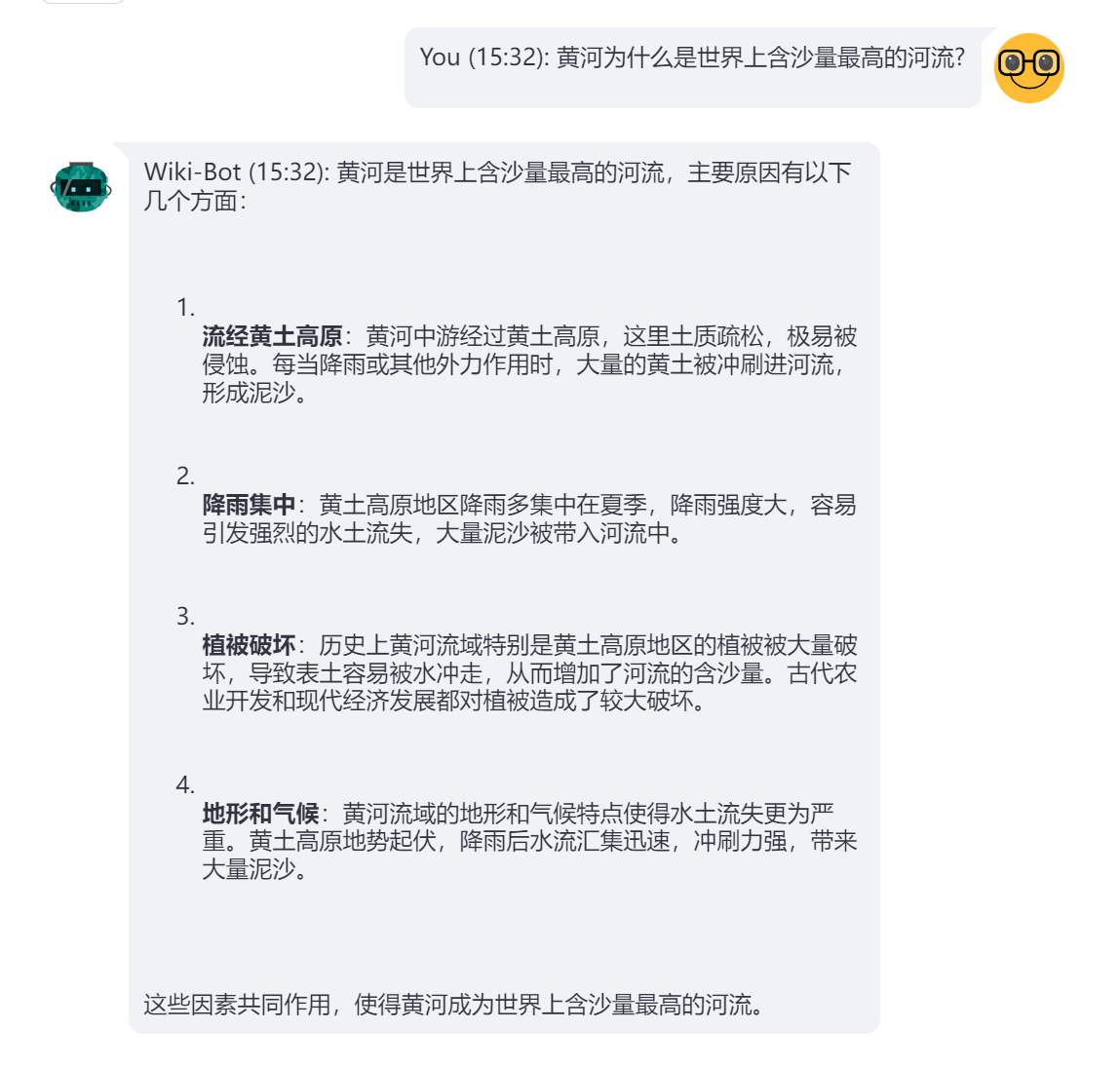
问题2:黄河为什么是世界上含沙量最高的河流?