一、需求 基于 LangChain 和 Streamlit 的 Web 应用,用于使用 LLM 和嵌入从 SQLite 数据库中搜索相关的 offer。用户可以输入与品牌、类别或零售商相关的搜索查询,也支持通过 SQL 语句进行搜索,应用程序将从数据库中检索并显示相关的 offer。该应用使用 OpenAI API 进行自然语言处理和嵌入生成。
SQLite 官网:https://www.sqlite.org/pragma.html#toc
SQLite 使用手册:https://www.runoob.com/sqlite/sqlite-select.html
二、方法
目标 :该方法的目标是基于产品类别、品牌或零售商查询从 offer_retailer 表中提取相关的offer。鉴于所需数据分散在 data 目录中的多个表中,采用了语言模型(LLM)来促进智能数据库查询。
数据库准备 :最初,使用存储在 data 目录中的 .csv 文件构建了一个本地 SQLite 数据库。这是通过 sqlite3 和 pandas 库实现的。
LLM 集成 :通过 langchain_experimental.sql.SQLDatabaseChain 实现了语言模型(LLM)与本地 SQLite 数据库的有效交互。
提示工程 :该方法的一个重要方面是制定合适的提示,以指导 LLM 最佳地检索和格式化数据库条目。通过多次迭代和实验来微调这个提示。
相似度评分 :为了确定检索结果与查询的相关性,进行了余弦相似度比较。使用 langchain_openai.OpenAIEmbeddings 生成嵌入进行比较,从而对结果进行排序。
Streamlit 集成 :最后一步是解析 LLM 的输出,并围绕它构建一个用户友好的 Streamlit 应用,允许用户进行交互式搜索。
三、环境 在开始之前,请确保满足以下要求:
安装所需的包:
1 pip install -r requirements.txt
确保您的 SQLite 数据库已设置好,并包含必要的表(brand_category,categories,offer_retailer)。
注意:streamlit版本需要<1.30,一般为1.29.0,否则启动会报以下错误。
四、代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 import osimport sqlite3import pandas as pdimport streamlit as stfrom llm import RetrievalLLMDATA_PATH = 'data' TABLES = ('brand_category' , 'categories' , 'offer_retailer' ) DB_NAME = 'offer_db.sqlite' PROMPT_TEMPLATE = """ 你会接收到一个查询,你的任务是从`offer_retailer`表中的`OFFER`字段检索相关offer。 查询可能是混合大小写的,所以也要搜索大写版本的查询。 重要的是,你可能需要使用数据库中其他表的信息,即:`brand_category`, `categories`, `offer_retailer`,来检索正确的offer。 不要虚构offer。如果在`offer_retailer`表中找不到offer,返回字符串:`NONE`。 如果你能从`offer_retailer`表中检索到offer,用分隔符`#`分隔每个offer。例如,输出应该是这样的:`offer1#offer2#offer3`。 如果SQLResult为空,返回`None`。不要生成任何offer。 这是查询:`{}` """ st.title("搜索offer 🔍" ) conn = sqlite3.connect('offer_db.sqlite' ) def is_sql_query (query ): sql_keywords = ['SELECT' , 'INSERT' , 'UPDATE' , 'DELETE' , 'CREATE' , 'DROP' , 'ALTER' ,'TRUNCATE' , 'MERGE' , 'CALL' , 'EXPLAIN' , 'DESCRIBE' , 'SHOW' ] query_upper = query.strip().upper() for keyword in sql_keywords: if query_upper.startswith(keyword): return True sql_pattern = re.compile (r'^\s*(SELECT|INSERT|UPDATE|DELETE|CREATE|DROP|ALTER|TRUNCATE|MERGE|CALL|EXPLAIN|DESCRIBE|SHOW)\s+' , re.IGNORECASE ) if sql_pattern.match (query): return True return False with st.form("search_form" ): query = st.text_input("通过类别、品牌或发布商搜索offer。" ) submitted = st.form_submit_button("搜索" ) retrieval_llm = RetrievalLLM( data_path=DATA_PATH, tables=TABLES, db_name=DB_NAME, openai_api_key=os.getenv('OPENAI_API_KEY' ), ) if submitted: if is_sql_query(query): st.write(pd.read_sql_query(query, conn)) else : retrieved_offers = retrieval_llm.retrieve_offers( PROMPT_TEMPLATE.format (query) ) if not retrieved_offers: st.text("未找到相关offer。" ) else : st.table(retrieval_llm.parse_output(retrieved_offers, query))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 import sqlite3import numpy as npimport pandas as pdfrom langchain_openai import OpenAIEmbeddingsfrom langchain_openai import OpenAIfrom langchain_community.utilities import SQLDatabasefrom langchain_experimental.sql import SQLDatabaseChainclass RetrievalLLM : """一个类,用于使用大型语言模型(LLM)检索和重新排序offer。 参数: data_path (str): 包含数据CSV文件的目录路径。 tables (list[str]): 数据CSV文件的名称列表。 db_name (str): 用于存储数据的SQLite数据库名称。 openai_api_key (str): OpenAI API密钥。 属性: data_path (str): 包含数据CSV文件的目录路径。 tables (list[str]): 数据CSV文件的名称列表。 db_name (str): 用于存储数据的SQLite数据库名称。 openai_api_key (str): OpenAI API密钥。 db (SQLDatabase): SQLite数据库连接。 llm (OpenAI): OpenAI LLM客户端。 embeddings (OpenAIEmbeddings): OpenAI嵌入客户端。 db_chain (SQLDatabaseChain): 与LLM集成的SQL数据库链。 """ def init (self, data_path, tables, db_name, openai_api_key ): self .data_path = data_path self .tables = tables self .db_name = db_name self .openai_api_key = openai_api_key dfs = {} for table in self .tables: dfs[table] = pd.read_csv(f"{self.data_path} /{table} .csv" ) with sqlite3.connect(self .db_name) as local_db: for table, df in dfs.items(): df.to_sql(table, local_db, if_exists="replace" ) self .db = SQLDatabase.from_uri(f"sqlite:///{self.db_name} " ) self .llm = OpenAI( temperature=0 , verbose=True , openai_api_key=self .openai_api_key ) self .embeddings = OpenAIEmbeddings(openai_api_key=self .openai_api_key) self .db_chain = SQLDatabaseChain.from_llm(self .llm, self .db) self .allow_reuse = True def retrieve_offers (self, prompt ): """使用LLM从数据库中检索offer。 参数: prompt (str): 用于检索offer的提示。 返回: list[str]: 检索到的offer列表。 """ retrieved_offers = self .db_chain.run(prompt) return None if retrieved_offers == "None" else retrieved_offers def get_embeddings (self, documents ): """使用LLM获取文档的嵌入。 参数: documents (list[str]): 文档列表。 返回: np.ndarray: 包含文档嵌入的NumPy数组。 """ if len (documents) == 1 : return np.asarray(self .embeddings.embed_query(documents[0 ])) else : embeddings_list = [] for document in documents: embeddings_list.append(self .embeddings.embed_query(document)) return np.asarray(embeddings_list) def parse_output (self, retrieved_offers, query ): """解析retrieve_offers()方法的输出并返回一个数据帧。 参数: retrieved_offers (list[str]): 检索到的offer列表。 query (str): 用于检索offer的查询。 返回: pd.DataFrame: 包含匹配相似度和offer的数据帧。 """ top_offers = retrieved_offers.split("#" ) query_embedding = self .get_embeddings([query]) offer_embeddings = self .get_embeddings(top_offers) sim_scores = np.dot(offer_embeddings, query_embedding.T).flatten() sim_scores = [p * 100 for p in sim_scores] df = ( pd.DataFrame({"匹配相似度 %" : sim_scores, "offer" : top_offers}) .sort_values(by=["匹配相似度 %" ], ascending=False ) .reset_index(drop=True ) ) df.index += 1 return df
五、运行 本地运行应用
应用运行后,打开浏览器并导航到 http://localhost:8501 访问offer搜索界面。
在文本输入框中输入您的搜索查询(品牌、类别或零售商)。
点击“搜索”按钮启动搜索。
匹配查询的相关 offer 将以表格形式显示。
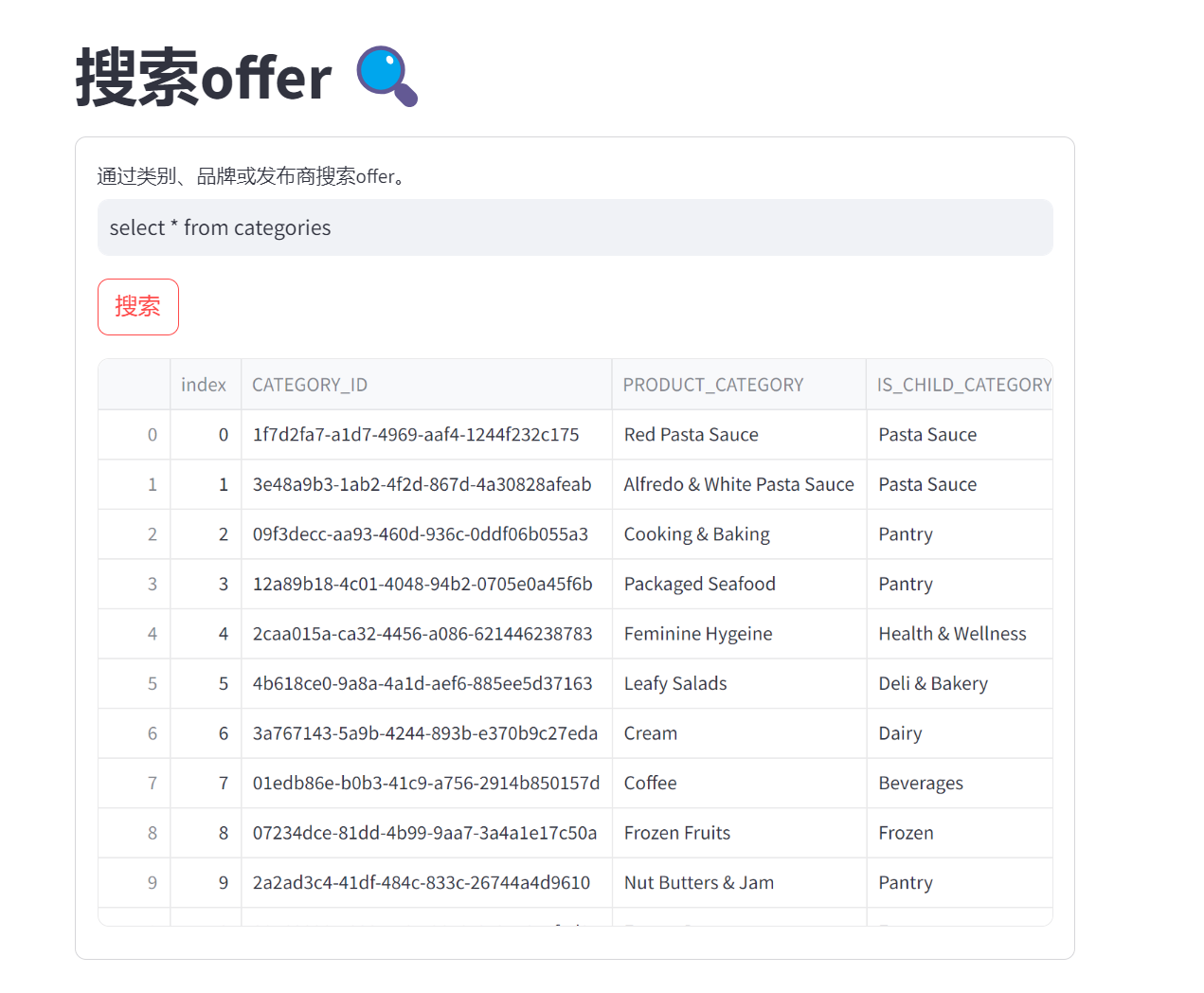
六、问答效果 问题1:select * from categories
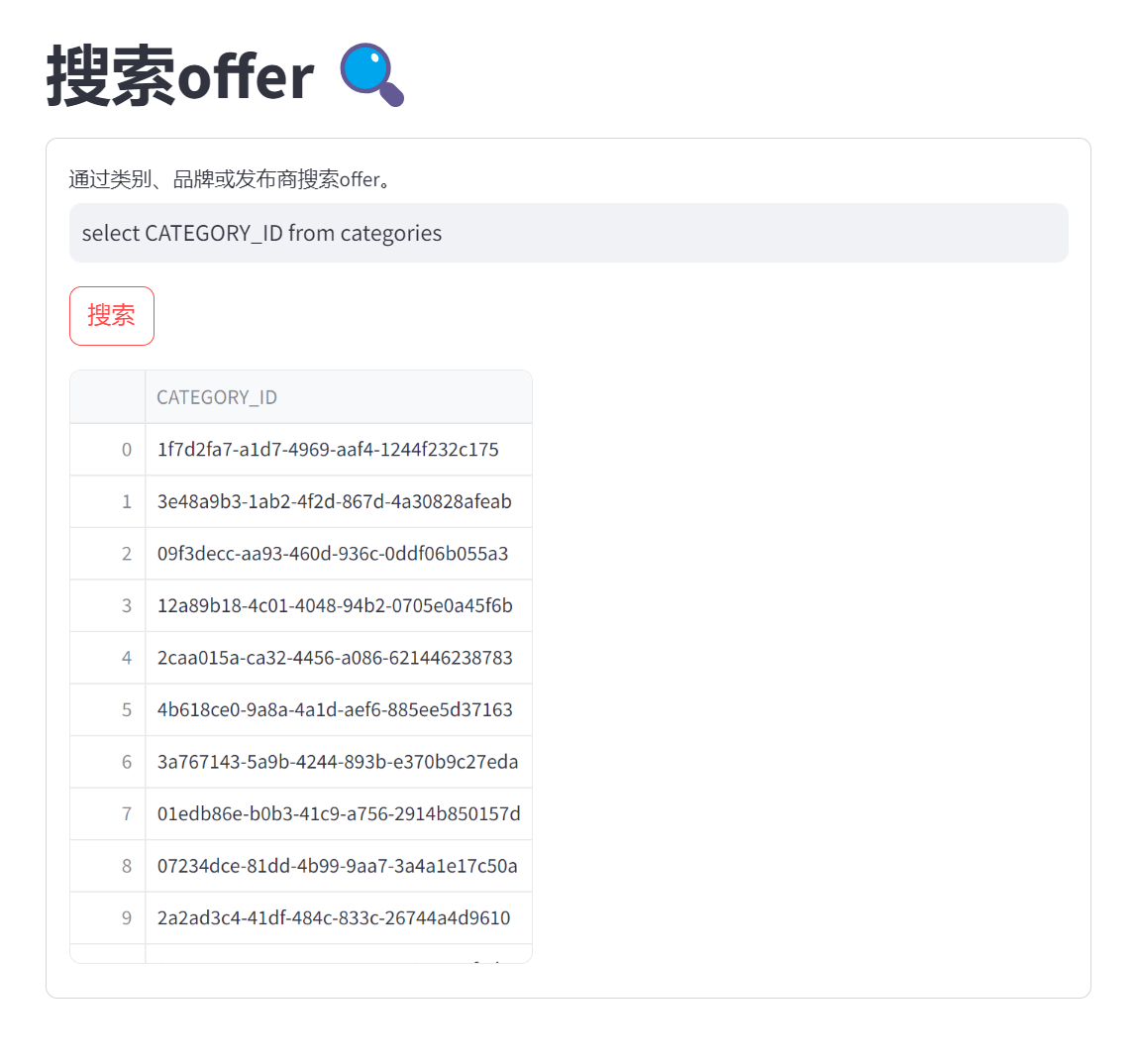
问题2:select CATEGORY_ID from categories
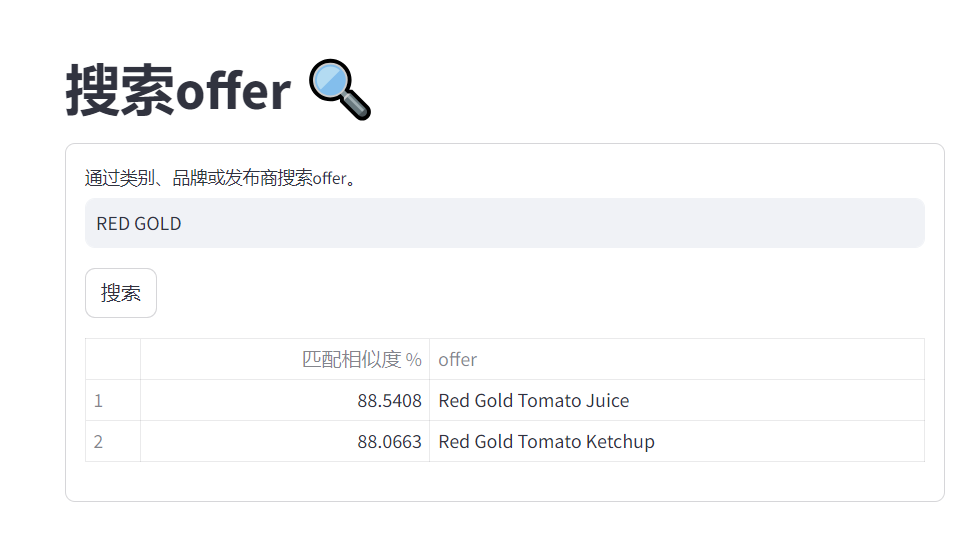
问题3:RED GOLD