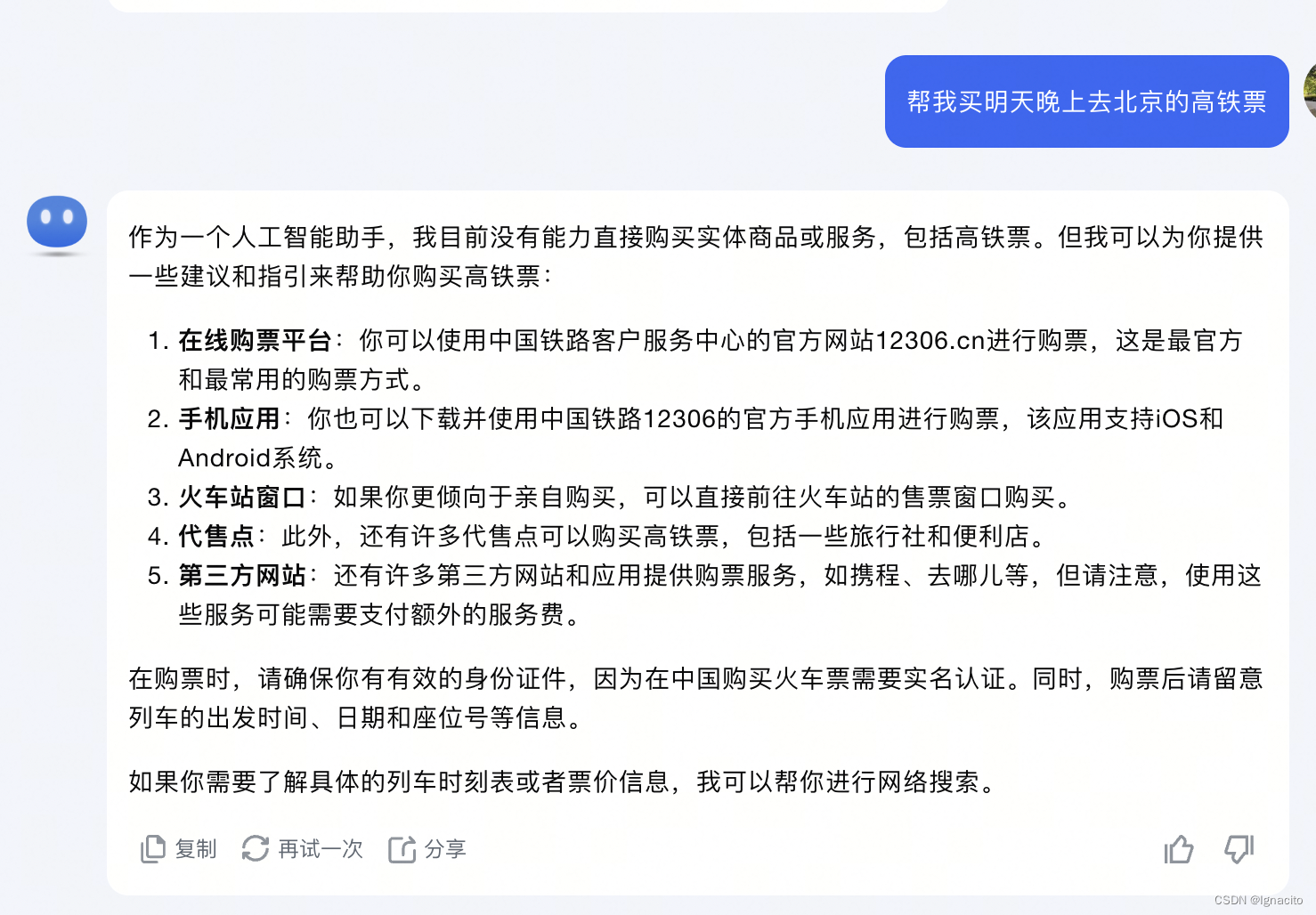
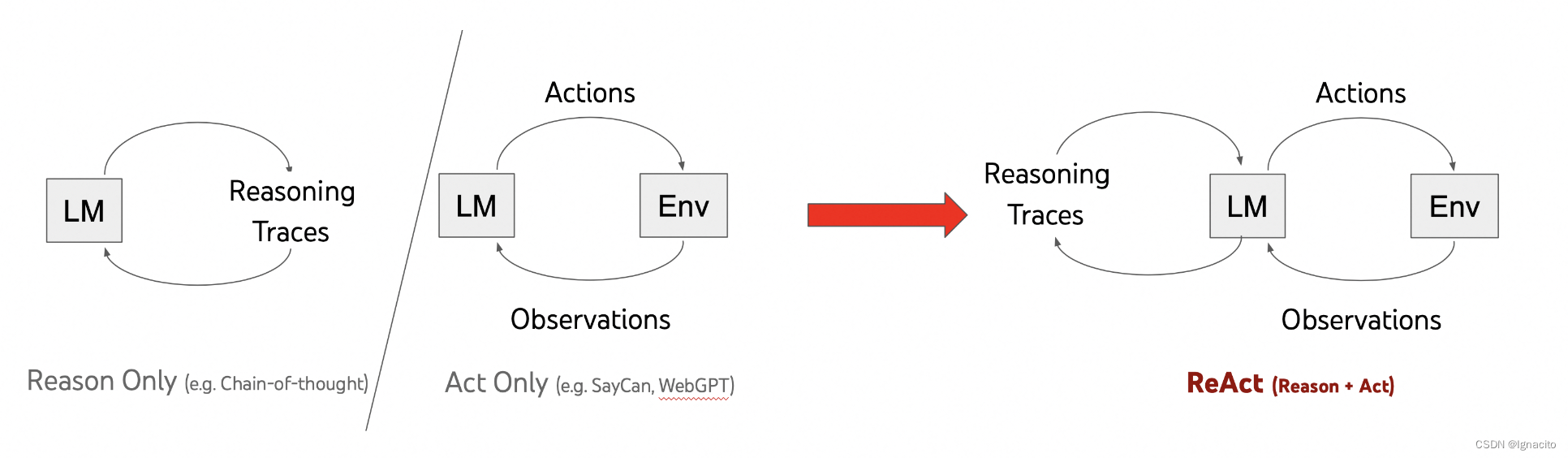
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
|
pip install langchain
pip install uuid
pip install pydantic
import json
import sys
from typing import List, Optional, Dict, Any, Tuple, Union
from uuid import UUID
from langchain.memory import ConversationTokenBufferMemory
from langchain.tools.render import render_text_description
from langchain_core.callbacks import BaseCallbackHandler
from langchain_core.language_models import BaseChatModel
from langchain_core.output_parsers import PydanticOutputParser, StrOutputParser
from langchain_core.outputs import GenerationChunk, ChatGenerationChunk, LLMResult
from langchain_core.prompts import PromptTemplate
from langchain_core.tools import StructuredTool
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field, ValidationError
from typing import List
from langchain_core.tools import StructuredTool
def search_train_ticket(
origin: str,
destination: str,
date: str,
departure_time_start: str,
departure_time_end: str
) -> List[dict[str, str]]:
"""按指定条件查询火车票"""
return [
{
"train_number": "G1234",
"origin": "北京",
"destination": "上海",
"departure_time": "2024-06-01 8:00",
"arrival_time": "2024-06-01 12:00",
"price": "100.00",
"seat_type": "商务座",
},
{
"train_number": "G5678",
"origin": "北京",
"destination": "上海",
"departure_time": "2024-06-01 18:30",
"arrival_time": "2024-06-01 22:30",
"price": "100.00",
"seat_type": "商务座",
},
{
"train_number": "G9012",
"origin": "北京",
"destination": "上海",
"departure_time": "2024-06-01 19:00",
"arrival_time": "2024-06-01 23:00",
"price": "100.00",
"seat_type": "商务座",
}
]
def purchase_train_ticket(
train_number: str,
) -> dict:
"""购买火车票"""
return {
"result": "success",
"message": "购买成功",
"data": {
"train_number": "G1234",
"seat_type": "商务座",
"seat_number": "7-17A"
}
}
search_train_ticket_tool = StructuredTool.from_function(
func=search_train_ticket,
name="查询火车票",
description="查询指定日期可用的火车票。",
)
purchase_train_ticket_tool = StructuredTool.from_function(
func=purchase_train_ticket,
name="购买火车票",
description="购买火车票。会返回购买结果(result), 和座位号(seat_number)",
)
finish_placeholder = StructuredTool.from_function(
func=lambda: None,
name="FINISH",
description="用于表示任务完成的占位符工具"
)
tools = [search_train_ticket_tool, purchase_train_ticket_tool, finish_placeholder]
prompt_text = """
你是强大的AI火车票助手,可以使用工具与指令查询并购买火车票
你的任务是:
{task_description}
你可以使用以下工具或指令,它们又称为动作或actions:
{tools}
当前的任务执行记录:
{memory}
按照以下格式输出:
任务:你收到的需要执行的任务
思考: 观察你的任务和执行记录,并思考你下一步应该采取的行动
然后,根据以下格式说明,输出你选择执行的动作/工具:
{format_instructions}
"""
final_prompt = """
你的任务是:
{task_description}
以下是你的思考过程和使用工具与外部资源交互的结果。
{memory}
你已经完成任务。
现在请根据上述结果简要总结出你的最终答案。
直接给出答案。不用再解释或分析你的思考过程。
"""
class Action(BaseModel):
"""结构化定义工具的属性"""
name: str = Field(description="工具或指令名称")
args: Optional[Dict[str, Any]] = Field(description="工具或指令参数,由参数名称和参数值组成")
class MyPrintHandler(BaseCallbackHandler):
"""自定义LLM CallbackHandler,用于打印大模型返回的思考过程"""
def __init__(self):
BaseCallbackHandler.__init__(self)
def on_llm_new_token(
self,
token: str,
*,
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,
run_id: UUID,
parent_run_id: Optional[UUID] = None,
**kwargs: Any,
) -> Any:
end = ""
content = token + end
sys.stdout.write(content)
sys.stdout.flush()
return token
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any:
end = ""
content = "\n" + end
sys.stdout.write(content)
sys.stdout.flush()
return response
class MyAgent:
def __init__(
self,
llm: BaseChatModel = ChatOpenAI(
model="gpt-4-turbo",
temperature=0,
model_kwargs={
"seed": 42
},
),
tools=None,
prompt: str = "",
final_prompt: str = "",
max_thought_steps: Optional[int] = 10,
):
if tools is None:
tools = []
self.llm = llm
self.tools = tools
self.final_prompt = PromptTemplate.from_template(final_prompt)
self.max_thought_steps = max_thought_steps
self.output_parser = PydanticOutputParser(pydantic_object=Action)
self.prompt = self.__init_prompt(prompt)
self.llm_chain = self.prompt | self.llm | StrOutputParser()
self.verbose_printer = MyPrintHandler()
def __init_prompt(self, prompt):
return PromptTemplate.from_template(prompt).partial(
tools=render_text_description(self.tools),
format_instructions=self.__chinese_friendly(
self.output_parser.get_format_instructions(),
)
)
def run(self, task_description):
"""Agent主流程"""
thought_step_count = 0
agent_memory = ConversationTokenBufferMemory(
llm=self.llm,
max_token_limit=4000,
)
agent_memory.save_context(
{"input": "\ninit"},
{"output": "\n开始"}
)
while thought_step_count < self.max_thought_steps:
print(f">>>>Round: {thought_step_count}<<<<")
action, response = self.__step(
task_description=task_description,
memory=agent_memory
)
if action.name == "FINISH":
break
observation = self.__exec_action(action)
print(f"----\nObservation:\n{observation}")
self.__update_memory(agent_memory, response, observation)
thought_step_count += 1
if thought_step_count >= self.max_thought_steps:
reply = "抱歉,我没能完成您的任务。"
else:
final_chain = self.final_prompt | self.llm | StrOutputParser()
reply = final_chain.invoke({
"task_description": task_description,
"memory": agent_memory
})
return reply
def __step(self, task_description, memory) -> Tuple[Action, str]:
"""执行一步思考"""
response = ""
for s in self.llm_chain.stream({
"task_description": task_description,
"memory": memory
}, config={
"callbacks": [
self.verbose_printer
]
}):
response += s
action = self.output_parser.parse(response)
return action, response
def __exec_action(self, action: Action) -> str:
observation = "没有找到工具"
for tool in self.tools:
if tool.name == action.name:
try:
observation = tool.run(action.args)
except ValidationError as e:
observation = (
f"Validation Error in args: {str(e)}, args: {action.args}"
)
except Exception as e:
observation = f"Error: {str(e)}, {type(e).__name__}, args: {action.args}"
return observation
@staticmethod
def __update_memory(agent_memory, response, observation):
agent_memory.save_context(
{"input": response},
{"output": "\n返回结果:\n" + str(observation)}
)
@staticmethod
def __chinese_friendly(string) -> str:
lines = string.split('\n')
for i, line in enumerate(lines):
if line.startswith('{') and line.endswith('}'):
try:
lines[i] = json.dumps(json.loads(line), ensure_ascii=False)
except:
pass
return '\n'.join(lines)
if name == "__main__":
my_agent = MyAgent(
tools=tools,
prompt=prompt_text,
final_prompt=final_prompt,
)
task = "帮我买24年6月1日早上去上海的火车票"
reply = my_agent.run(task)
print(reply)
|