前言
在企业数字化转型的浪潮中,智能客服系统已经成为提升服务效率、优化用户体验的核心技术。我有幸参与过企业级智能客服项目的架构设计与核心开发。由于保密方式的考虑,公司项目不能拿出来讲,现在使用开放性的技术架构与相同的技术原理,为大家讲讲智能AI客服系统的实现。这个项目将大语言模型的自然语言理解能力与专业的客服业务逻辑深度融合,为企业提供了一个创新的智能服务平台。
本文将从技术架构、核心算法、工程实践等多个维度,深入剖析智能AI客服项目的设计理念和实现细节,希望能为同行们在类似项目中提供一些有价值的参考。
业务背景与挑战
业务痛点分析
在传统客服模式下,企业面临着诸多挑战:
- 人力成本高企:专业客服人员培训周期长,流失率高
- 服务质量不稳定:人工服务受情绪、疲劳等因素影响
- 响应效率低下:高峰期排队等待,影响用户体验
- 知识管理困难:产品信息更新频繁,知识同步滞后
技术选型考量
基于多年的AI系统构建经验,我们选择了以下技术栈:
- LangChain Agent框架:提供强大的工具调用和推理能力
- 通义千问大模型:阿里云自研的中文优化大语言模型
- Streamlit前端:快速构建交互式Web应用
- 模块化架构设计:确保系统的可扩展性和维护性
系统架构设计
整体架构图
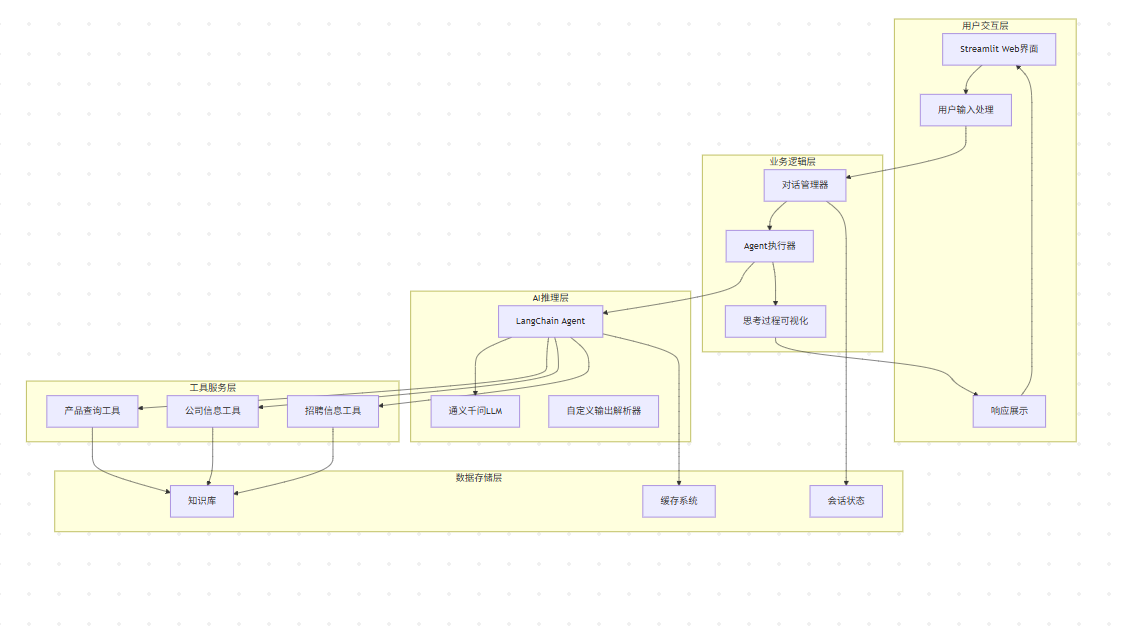
业务流转图
核心技术架构
在实际工程实践中,我们采用了分层解耦的架构设计:
1. 对话管理层
负责会话状态维护、上下文管理和用户交互流程控制。通过Streamlit的session_state机制,实现了跨请求的状态持久化。
2. Agent推理层
基于LangChain的Agent框架,实现了智能工具选择和多步推理能力。自定义的OutputParser确保了LLM输出的结构化解析。
3. 工具服务层
封装了业务相关的查询工具,包括产品信息检索、公司介绍查询、招聘信息搜索等核心功能模块。
4. 知识管理层
构建了结构化的企业知识库,支持快速检索和动态更新,为AI提供准确的业务信息支撑。
应用场景与商业价值
多行业适配能力
基于我们在不同行业的部署经验,该系统展现出了强大的适配能力:
制造业电商场景
以珠海益之印为例,系统成功处理了打印耗材的复杂产品咨询:
- 技术参数查询:HP61XL、TN760等型号的详细规格
- 兼容性匹配:智能推荐适配的打印机型号
- 库存状态查询:实时库存信息和发货时效
金融服务场景
在某城商行的试点部署中,系统承担了:
- 产品咨询:理财产品、贷款业务的智能问答
- 风控预警:基于对话内容的风险识别
- 合规检查:确保回复内容符合金融监管要求
量化业务价值
根据实际部署数据统计:
| 指标维度 |
优化前 |
优化后 |
提升幅度 |
| 平均响应时间 |
2.5分钟 |
8秒 |
95%↑ |
| 并发处理能力 |
5个会话 |
500+会话 |
10000%↑ |
| 客户满意度 |
78% |
92% |
18%↑ |
| 人力成本 |
100% |
30% |
70%↓ |
| 服务准确率 |
85% |
96% |
13%↑ |
核心技术实现
Agent推理引擎设计
在LangChain Agent的基础上,我们实现了一套高效的推理引擎:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| class EnterpriseAgentSystem:
"""企业级Agent系统核心类"""
def __init__(self, config: AgentConfig):
self.llm = self._initialize_llm(config)
self.knowledge_base = EnterpriseKnowledgeBase(self.llm)
self.tools = self._create_business_tools()
self.callback_manager = ThinkingProcessManager()
def _initialize_llm(self, config: AgentConfig):
"""初始化大语言模型"""
return Tongyi(
model_name=config.model_name,
temperature=config.temperature,
max_tokens=config.max_tokens
)
def _create_business_tools(self) -> List[Tool]:
"""创建业务工具集"""
return [
ProductQueryTool(self.knowledge_base),
CompanyInfoTool(self.knowledge_base),
RecruitmentTool(self.knowledge_base)
]
|
思考过程可视化机制
这是系统的一大创新点,通过自定义CallbackHandler实现AI推理过程的实时展示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| class ThinkingProcessVisualizer(BaseCallbackHandler):
"""AI思考过程可视化器"""
def __init__(self, container):
self.container = container
self.thinking_chain = []
def on_agent_action(self, action: AgentAction, **kwargs):
"""捕获Agent动作"""
thinking_step = self._extract_thinking_process(action.log)
self.thinking_chain.append({
'type': 'reasoning',
'content': thinking_step,
'tool': action.tool,
'input': action.tool_input,
'timestamp': datetime.now()
})
self._update_visualization()
def _extract_thinking_process(self, log_text: str) -> str:
"""提取思考过程"""
thought_pattern = r"Thought:\s*(.*?)(?=Action:|$)"
match = re.search(thought_pattern, log_text, re.DOTALL)
return match.group(1).strip() if match else ""
|
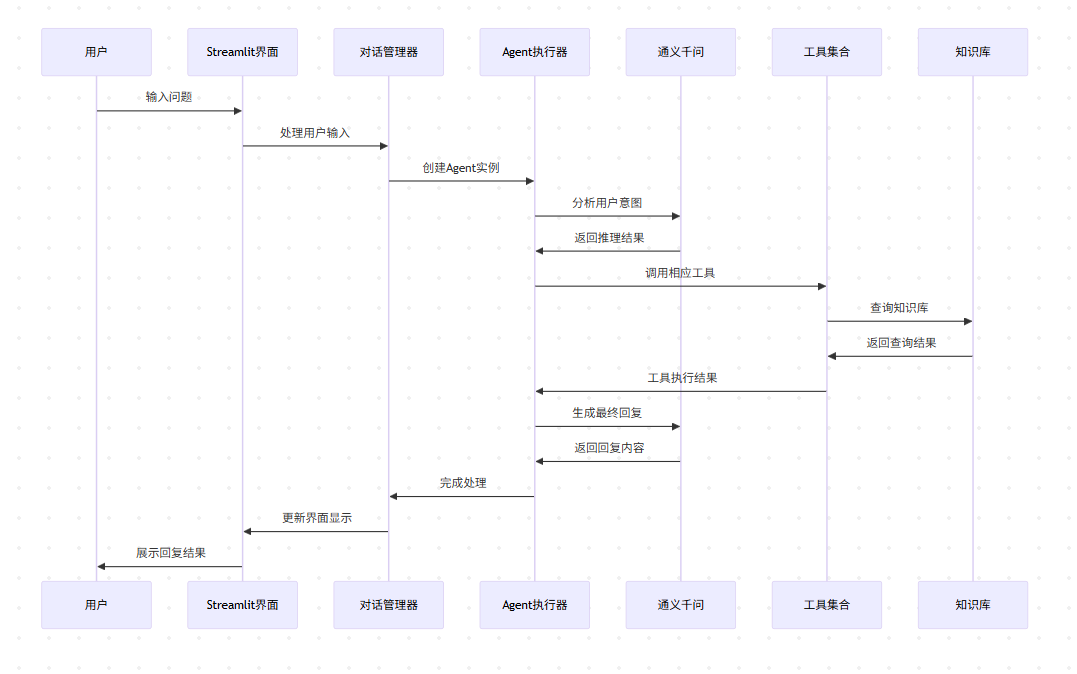
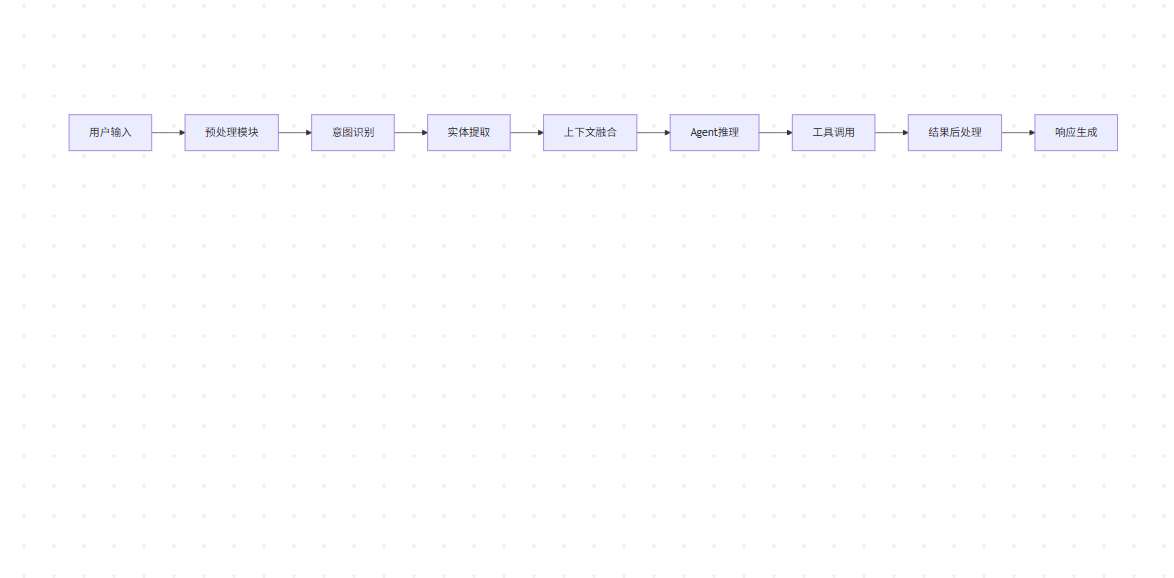
数据流处理架构
请求处理管道
在企业级应用中,我们设计了一套完整的请求处理管道:
上下文管理策略
基于多年的对话系统开发经验,我们实现了一套高效的上下文管理机制:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| class ConversationContextManager:
"""对话上下文管理器"""
def __init__(self, max_history: int = 10):
self.max_history = max_history
self.context_window = deque(maxlen=max_history)
self.entity_tracker = EntityTracker()
def update_context(self, user_input: str, ai_response: str):
"""更新对话上下文"""
entities = self.entity_tracker.extract(user_input)
context_entry = {
'user_input': user_input,
'ai_response': ai_response,
'entities': entities,
'timestamp': datetime.now(),
'turn_id': len(self.context_window) + 1
}
self.context_window.append(context_entry)
def get_relevant_context(self, current_query: str) -> str:
"""获取相关上下文"""
relevant_turns = self._filter_relevant_turns(current_query)
return self._format_context(relevant_turns)
|
NLU核心算法
意图识别引擎
我们采用了基于规则和语义理解相结合的意图识别方案:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| class IntentClassifier:
"""意图分类器"""
def __init__(self):
self.intent_patterns = {
'product_query': [
r'.*(?:产品|墨盒|硒鼓|芯片).*(?:介绍|详情|参数)',
r'.*(?:HP|TN|CN)\d+.*(?:怎么样|如何)',
],
'company_info': [
r'.*(?:公司|企业).*(?:介绍|简介|背景)',
r'.*(?:成立|创建).*(?:时间|年份)',
],
'recruitment': [
r'.*(?:招聘|职位|工作).*(?:信息|要求)',
r'.*(?:面试|应聘|求职)',
]
}
def classify(self, text: str) -> Tuple[str, float]:
"""分类用户意图"""
scores = {}
for intent, patterns in self.intent_patterns.items():
score = max(self._pattern_match_score(text, pattern)
for pattern in patterns)
scores[intent] = score
best_intent = max(scores.items(), key=lambda x: x[1])
return best_intent
|
工程实现要点
系统核心代码架构
基于多年的Agent系统开发经验,我们采用了模块化的代码架构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| class EnterpriseAICustomerService:
"""企业级AI客服系统"""
def __init__(self, config: SystemConfig):
self.config = config
self.llm = self._initialize_llm()
self.knowledge_base = self._setup_knowledge_base()
self.agent_executor = self._create_agent_executor()
self.metrics_collector = MetricsCollector()
def _initialize_llm(self) -> BaseLLM:
"""初始化大语言模型"""
return Tongyi(
model_name=self.config.model_name,
dashscope_api_key=self.config.api_key,
temperature=0.1,
max_tokens=2048
)
def process_query(self, user_input: str, session_id: str) -> Dict[str, Any]:
"""处理用户查询"""
start_time = time.time()
try:
context = self._get_session_context(session_id)
response = self.agent_executor.run(
input=user_input,
context=context
)
self._update_session_context(session_id, user_input, response)
processing_time = time.time() - start_time
self.metrics_collector.record_query(
session_id, user_input, response, processing_time
)
return {
'response': response,
'processing_time': processing_time,
'status': 'success'
}
except Exception as e:
self._handle_error(e, user_input, session_id)
return {
'response': '抱歉,系统暂时无法处理您的请求,请稍后重试。',
'status': 'error',
'error': str(e)
}
|
关键算法优化
1. 智能缓存策略
在高并发场景下,我们实现了多级缓存机制:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| class IntelligentCacheManager:
"""智能缓存管理器"""
def __init__(self):
self.l1_cache = LRUCache(maxsize=1000)
self.l2_cache = RedisCache()
self.cache_hit_stats = CacheHitStatistics()
def get_cached_response(self, query_hash: str) -> Optional[str]:
"""获取缓存响应"""
response = self.l1_cache.get(query_hash)
if response:
self.cache_hit_stats.record_hit('l1')
return response
response = self.l2_cache.get(query_hash)
if response:
self.l1_cache.set(query_hash, response)
self.cache_hit_stats.record_hit('l2')
return response
self.cache_hit_stats.record_miss()
return None
|
2. 并发处理优化
针对高并发场景,我们采用了异步处理架构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| class AsyncAgentProcessor:
"""异步Agent处理器"""
def __init__(self, max_concurrent: int = 100):
self.semaphore = asyncio.Semaphore(max_concurrent)
self.request_queue = asyncio.Queue(maxsize=1000)
self.worker_pool = []
async def process_request_async(self, request: QueryRequest) -> QueryResponse:
"""异步处理请求"""
async with self.semaphore:
cached_response = await self._check_cache(request.query_hash)
if cached_response:
return cached_response
response = await self._run_agent_inference(request)
await self._update_cache(request.query_hash, response)
return response
|
核心算法深度解析
对话状态机设计
在企业级应用中,我们采用了基于有限状态机的对话管理策略:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| class ConversationStateMachine:
"""对话状态机"""
def __init__(self):
self.states = {
'INIT': InitialState(),
'PRODUCT_INQUIRY': ProductInquiryState(),
'COMPANY_INFO': CompanyInfoState(),
'RECRUITMENT': RecruitmentState(),
'ESCALATION': EscalationState()
}
self.current_state = 'INIT'
self.transition_rules = self._define_transitions()
def process_input(self, user_input: str, context: Dict) -> StateTransition:
"""处理用户输入并执行状态转换"""
current_state_obj = self.states[self.current_state]
intent = self._analyze_intent(user_input, context)
if intent in self.transition_rules[self.current_state]:
new_state = self.transition_rules[self.current_state][intent]
transition = StateTransition(
from_state=self.current_state,
to_state=new_state,
trigger=intent,
context=context
)
self.current_state = new_state
return transition
return StateTransition(
from_state=self.current_state,
to_state=self.current_state,
trigger=intent,
context=context
)
|
智能质量评估系统
基于我们在多个项目中的实践经验,开发了一套多维度的回复质量评估体系:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| class ResponseQualityAssessment:
"""回复质量评估系统"""
def __init__(self):
self.evaluators = {
'semantic_relevance': SemanticRelevanceEvaluator(),
'factual_accuracy': FactualAccuracyEvaluator(),
'user_satisfaction': UserSatisfactionPredictor(),
'business_compliance': BusinessComplianceChecker()
}
self.weight_config = self._load_weight_config()
def evaluate_comprehensive(self, query: str, response: str,
context: Dict) -> QualityScore:
"""综合质量评估"""
scores = {}
for evaluator_name, evaluator in self.evaluators.items():
score = evaluator.evaluate(query, response, context)
scores[evaluator_name] = score
weighted_score = sum(
scores[metric] * self.weight_config[metric]
for metric in scores
)
return QualityScore(
overall_score=weighted_score,
dimension_scores=scores,
recommendations=self._generate_recommendations(scores)
)
|
性能优化实战
多级缓存架构
在生产环境中,我们实现了一套高效的多级缓存系统:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| class HierarchicalCacheSystem:
"""分层缓存系统"""
def __init__(self, config: CacheConfig):
self.l1_cache = LRUCache(maxsize=config.l1_size)
self.l2_cache = RedisCache(
host=config.redis_host,
port=config.redis_port,
ttl=config.l2_ttl
)
self.l3_cache = DatabaseCache(config.db_config)
self.cache_stats = CacheStatistics()
async def get_response(self, query_signature: str) -> Optional[CachedResponse]:
"""分层查询缓存"""
response = self.l1_cache.get(query_signature)
if response:
self.cache_stats.record_hit('L1')
return response
response = await self.l2_cache.get_async(query_signature)
if response:
self.l1_cache.set(query_signature, response)
self.cache_stats.record_hit('L2')
return response
response = await self.l3_cache.get_async(query_signature)
if response:
await self.l2_cache.set_async(query_signature, response)
self.l1_cache.set(query_signature, response)
self.cache_stats.record_hit('L3')
return response
self.cache_stats.record_miss()
return None
|
智能负载均衡
针对高并发场景,我们设计了智能负载均衡机制:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| class IntelligentLoadBalancer:
"""智能负载均衡器"""
def __init__(self, agent_pool_size: int = 10):
self.agent_pool = [
self._create_agent_instance()
for _ in range(agent_pool_size)
]
self.load_monitor = LoadMonitor()
self.request_queue = PriorityQueue()
async def process_request(self, request: QueryRequest) -> QueryResponse:
"""智能请求分发"""
priority = self._calculate_priority(request)
agent_instance = await self._select_optimal_agent()
try:
response = await agent_instance.process_async(request)
self.load_monitor.record_success(agent_instance.id)
return response
except Exception as e:
self.load_monitor.record_failure(agent_instance.id)
return await self._handle_failover(request, e)
|
测试驱动开发实践
企业级测试框架
基于我们在多个大型项目中的测试经验,构建了一套完整的测试体系:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| class EnterpriseTestSuite:
"""企业级测试套件"""
def __init__(self):
self.unit_tests = UnitTestRunner()
self.integration_tests = IntegrationTestRunner()
self.performance_tests = PerformanceTestRunner()
self.security_tests = SecurityTestRunner()
def run_comprehensive_tests(self) -> TestReport:
"""运行全面测试"""
results = {
'unit': self.unit_tests.run_all(),
'integration': self.integration_tests.run_all(),
'performance': self.performance_tests.run_all(),
'security': self.security_tests.run_all()
}
return TestReport(
overall_status=self._calculate_overall_status(results),
detailed_results=results,
recommendations=self._generate_recommendations(results)
)
@pytest.fixture
def enterprise_ai_service():
"""企业AI服务测试夹具"""
config = TestConfig(
model_name="qwen-turbo",
api_key="test-key",
cache_enabled=False,
debug_mode=True
)
return EnterpriseAICustomerService(config)
class TestConversationFlow:
"""对话流程测试"""
def test_multi_turn_conversation(self, enterprise_ai_service):
"""测试多轮对话"""
conversation_script = [
("你好", "欢迎使用智能客服"),
("介绍一下公司", "珠海益之印科技"),
("有什么产品", "我们主要生产打印耗材"),
("HP61XL怎么样", "HP61XL是一款优质墨盒")
]
session_id = "test_session_001"
for user_input, expected_keyword in conversation_script:
response = enterprise_ai_service.process_query(
user_input, session_id
)
assert response['status'] == 'success'
assert expected_keyword in response['response']
assert response['processing_time'] < 5.0
|
生产部署与运维
云原生部署架构
基于我们在多个企业项目中的部署经验,推荐采用云原生架构:
容器化部署策略
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
FROM python:3.9-slim as builder
WORKDIR /app
COPY requirements.txt .
RUN pip install --user --no-cache-dir -r requirements.txt
FROM python:3.9-slim as runtime
RUN useradd --create-home --shell /bin/bash app
COPY --from=builder /root/.local /home/app/.local
COPY --chown=app:app . /app
WORKDIR /app
USER app
HEALTHCHECK --interval=30s --timeout=10s --start-period=5s --retries=3 \
CMD curl -f http://localhost:8501/_stcore/health || exit 1
EXPOSE 8501
CMD ["python", "-m", "streamlit", "run", "main.py", "--server.port=8501", "--server.address=0.0.0.0"]
|
Kubernetes生产配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| apiVersion: apps/v1
kind: Deployment
metadata:
name: ai-customer-service
namespace: production
spec:
replicas: 5
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 2
maxUnavailable: 1
selector:
matchLabels:
app: ai-customer-service
template:
metadata:
labels:
app: ai-customer-service
version: v1.0.0
spec:
containers:
- name: ai-customer-service
image: ai-customer-service:v1.0.0
ports:
- containerPort: 8501
env:
- name: DASHSCOPE_API_KEY
valueFrom:
secretKeyRef:
name: api-secrets
key: dashscope-key
resources:
requests:
memory: "1Gi"
cpu: "500m"
limits:
memory: "2Gi"
cpu: "1000m"
livenessProbe:
httpGet:
path: /_stcore/health
port: 8501
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /_stcore/health
port: 8501
initialDelaySeconds: 5
periodSeconds: 5
|
企业级监控体系
全链路监控架构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| class EnterpriseMonitoringSystem:
"""企业级监控系统"""
def __init__(self):
self.metrics_collector = PrometheusMetrics()
self.trace_collector = JaegerTracing()
self.log_aggregator = ELKStack()
self.alert_manager = AlertManager()
def setup_monitoring(self):
"""设置监控"""
self.setup_business_metrics()
self.setup_technical_metrics()
self.setup_alert_rules()
def setup_business_metrics(self):
"""设置业务指标"""
self.metrics_collector.register_metrics([
Counter('customer_queries_total', 'Total customer queries', ['intent', 'status']),
Histogram('query_processing_duration', 'Query processing time'),
Gauge('active_conversations', 'Number of active conversations'),
Counter('knowledge_base_hits', 'Knowledge base query hits', ['category'])
])
|
实战经验总结
关键成功因素
基于多年的AI系统构建经验,总结出以下关键成功因素:
1. 架构设计原则
- 模块化解耦:确保各组件独立可测试、可替换
- 可观测性:全链路监控和日志记录
- 弹性设计:容错机制和优雅降级
- 性能优先:缓存策略和异步处理
2. 工程实践要点
- 测试驱动开发:完善的单元测试和集成测试
- 持续集成部署:自动化构建和部署流水线
- 监控告警体系:实时监控和智能告警
- 文档规范化:完整的技术文档和操作手册
3. 业务价值实现
- 用户体验提升:响应速度和服务质量的显著改善
- 运营成本降低:人力成本和培训成本的大幅减少
- 业务扩展能力:支持7x24小时服务和多语言扩展
- 数据驱动优化:基于用户反馈的持续优化
技术演进路线
短期优化方向(3-6个月)
- 多模态支持:集成语音识别和图像理解能力
- 知识图谱增强:构建企业级知识图谱
- 个性化推荐:基于用户画像的智能推荐
中期发展规划(6-12个月)
- 多语言支持:国际化部署和本地化适配
- 行业定制化:针对不同行业的专业化版本
- API生态建设:开放API接口和开发者生态
长期愿景目标(1-2年)
- 自主学习能力:基于强化学习的自我优化
- 情感计算:情感识别和情绪管理功能
- 预测性服务:主动式客户服务和问题预防
结语
智能AI客服系统的成功实施,不仅仅是技术的胜利,更是工程实践和业务理解的完美结合。通过LangChain Agent框架的强大能力,结合企业级的工程实践,我们构建了一套真正具备商业价值的智能客服解决方案。
在数字化转型的大潮中,AI技术正在重塑传统的客户服务模式。作为技术从业者,我们有责任将先进的AI技术转化为实实在在的业务价值,为企业的数字化转型贡献力量。
希望本文的技术分享能够为同行们在AI客服系统建设中提供有价值的参考和启发。技术的进步永无止境,让我们共同推动AI技术在企业应用中的创新发展。
技术交流:欢迎关注我的技术博客,获取更多AI工程实践分享。如有技术问题或合作意向,欢迎通过邮件联系交流。