一、背景
在做公众号爆文内容的时候,我现在用的是 Perplexity 里的 Claude 4 Sonnet 模型来帮我生成文章。这个模型写出来的内容自然、有逻辑,而且不像很多 AI 那样一读就“假”,非常适合写公众号。
不过,每次用它生成文章的操作流程其实都一模一样:先打开 Perplexity 网站,然后把提前写好的提示词复制进去,等待生成好文章,随后下载 Markdown 文件,最后再手动排版、发布。这一整套流程差不多要 10 分钟,虽然也不算太久,但每天重复做这些机械动作,说实话挺费神,也挺浪费时的。
于是我就开始琢磨:这些重复的步骤能不能自动化?比如,我只需要提前把提示词准备好,程序就可以帮我自动打开网站、粘贴提示词、生成文章、下载文件——整个过程我都不用动手。最后我只需要花点时间排版、点击发布,这样不仅节省大量时间,还能让我把精力花在更重要的地方。
一)模型选择
为什么我选的是 Perplexity,而不是别的 AI 工具?主要有三个原因:
Perplexity 是可以联网的这一点非常重要。很多大模型虽然看起来很强,但信息是“闭门造车”的,经常一本正经地胡说八道。而 Perplexity 可以实时上网查资料,生成的内容更靠谱,也更接近最新的热点和趋势。同时相同的提示词,每次生成的内容不同。
它可以调用 Claude 模型。我自己测试过不少 AI 模型,写文章最自然、最不带“AI 味”的就是 Claude。它写出来的东西读起来像真人写的,不会干巴巴或尴尬,非常适合用在公众号里。
性价比真的高。Perplexity Pro 一年的会员,闲鱼上不到 70 块就能搞定。相较于 claude pro 每月 20 美金,这个简直是真香。唯一的问题是需要代理。
二)方案选择
之前我也尝试过用影刀 RPA 来实现网站自动化操作,比如自动打开网页、输入提示词、下载文件等。这类工具对非程序员很友好,逻辑也比较清晰。
但在实际使用中,我始终感觉不太顺手。操作流程看起来简单,但一旦遇到需要做判断、分支等稍复杂的逻辑时,学习成本就明显上来了。而且整个搭建过程对我来说比较别扭,效率也不高。
最终我还是选择用代码的方式来实现这些自动化功能。虽然前期写代码花了一些时间,但逻辑更灵活,后续维护也更轻松,整体体验比用可视化工具舒服得多。(可能也有自己是程序员的视角)
二、核心难点
一)cloudflare 验证如何过
自己常用浏览器配置,而非空白配置或其他配置。这种方式下,cloudflare 的验证会自动跳过。查看方法是自动化工具打开的浏览器,可以查看到之前的历史记录、登录状态。
在自己浏览器环境下打开 Perplexity 网站时,卡在 Cloudflare 的安全验证页面,需要手动点一下才能跳转到正常的搜索界面。这个问题的解决方式其实也很简单:多用几次 Perplexity 网站,保持登录状态,Cloudflare 就不会频繁弹出验证了。等网站“认出”你是正常用户后,后续基本可以自动跳转,不再卡在验证环节。
二)程序理解需要需要点击的位置
在让程序自动点击网页上的按钮之前,我们需要先搞清楚这个按钮在网页代码中的位置。就像你要告诉程序:‘去点这个地方’。即通过页面获取到需要点击位置的前端代码。
大模型可以帮我们看懂网页的代码,然后自动写出一段程序,告诉去点击这里。后面有关于具体的提示词写法(也很简单)。
介绍一个自己在处理正则表达式的一个小技巧:
大模型在处理正则表达式上面有很高的造诣,最起码比我要强(毕竟是真的不懂😧)。关于处理此类问题我采用最多的提示词是:
1 | 采用xx语言帮我实现正则表达式,输入的内容是:<原始内容>,输出的内容是:<提取内容>,请你帮我进行实现。 |
三、整体方案
根据日常的操作总结,分为以下 5 个步骤:
打开浏览器
打开 perplexity 网站
选择 Claude 4.0 Sonnet 模型
输入提示词并进行检索
导出 markdown 文件
四、操作步骤
一) 环境准备
1、下载 miniconda
下载地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/ ,推荐下载 Miniconda3-py312 的版本
2、conda 修改清华源
在 conda 命令行下输入
1 | conda config --set show_channel_urls yes |
输入上述命令,可以直接生成。condara 文件。
修改.condarc 文件内容如下:
1 | channels: |
更多具体可参考:
3、pip 修改为阿里源
1 | pip config set global.index-url https://mirrors.aliyun.com/pypi/simple |
4、创建新环境
1 | conda create -n <环境名> python=3.12 |
二)获取页面中的前端代码
鼠标右键单击就可以看到《检查》,点击后就可以看到对应的前端代码,然后直接双击代码就可以看到页面上哪部分被选中。然后就可以直接复制前端的代码。
三)开发阶段
1、创建基础代码提示词
1 | python 使用selenium 打开perplexity 网站。 |
Windsurf 生成内容:
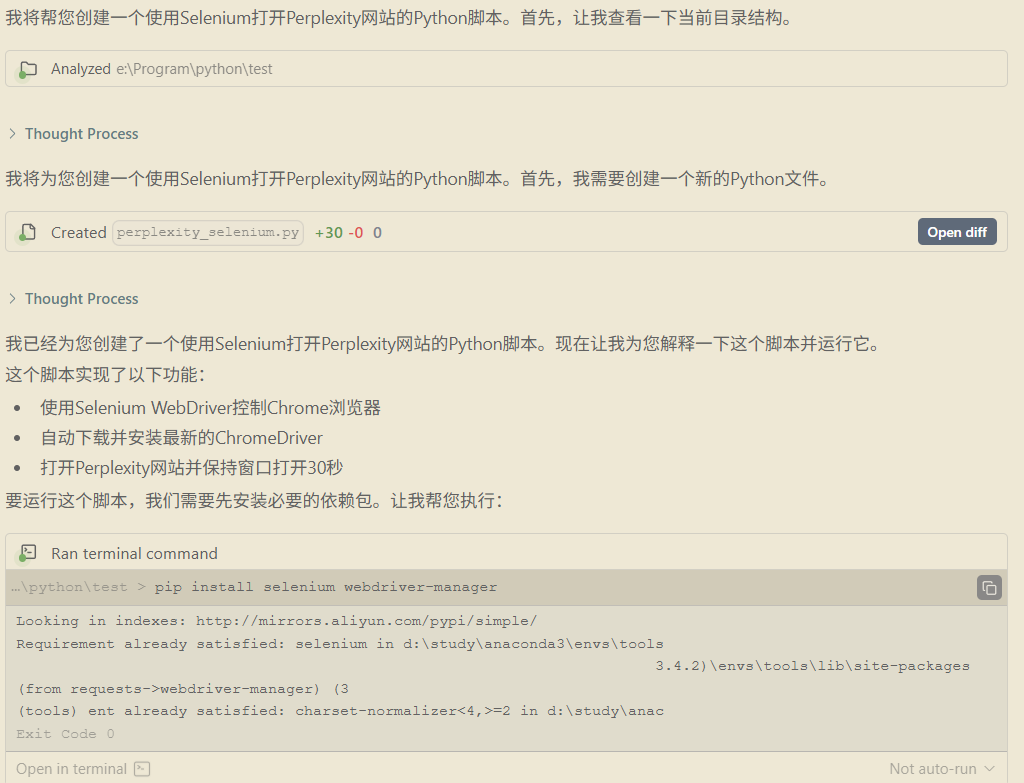
运行结果:
打开后发现,没有加载本机的配置文件及会出现目前浏览器处于调试状态。
没有加载本机的配置文件可以通过历史记录等信息查看;浏览器处于调试状态是打开浏览器后可以看到有一行小字的。
2、根据上面出现的问题,输入以下提示词:
1 | 在配置中添加,用户的配置文件参数,同时打开的页面中有debug的内容,这部分需要去除 |
Windsurf 生成内容:
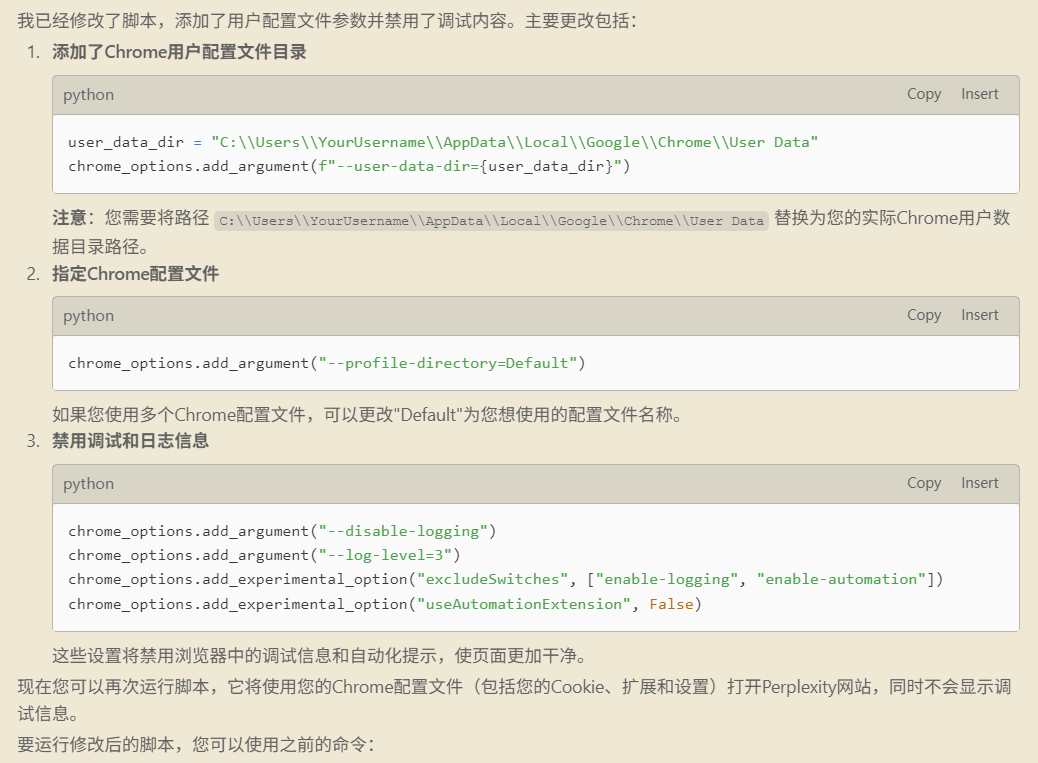
运行结果:
只打开了 chrome 浏览器,没有打开 perplexity 网站,同时出现错误内容输出
3、根据具体错误及具体的要求(加载用户数据),给出以下提示词:
1 | driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options),出现这样子的 错误:Message: session not created: probably user data directory is already in use, please specify a unique value for --user-data-dir argument, or don't use --user-data-dir 。但是我还需要加载用户数据。应该怎么进行修改 @web |
这是一个失败的经历,Windsurf 生成内容:
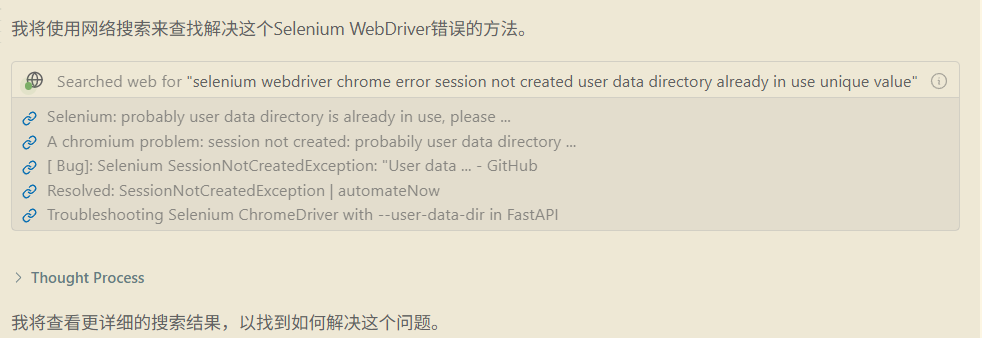
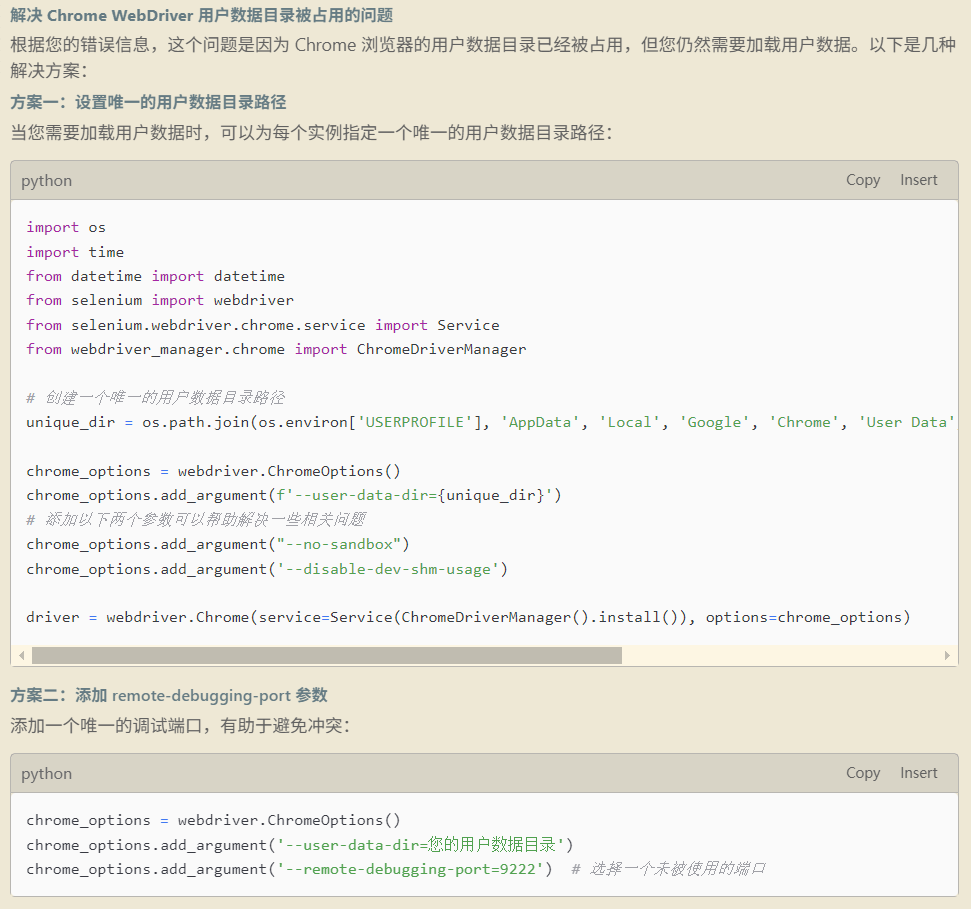
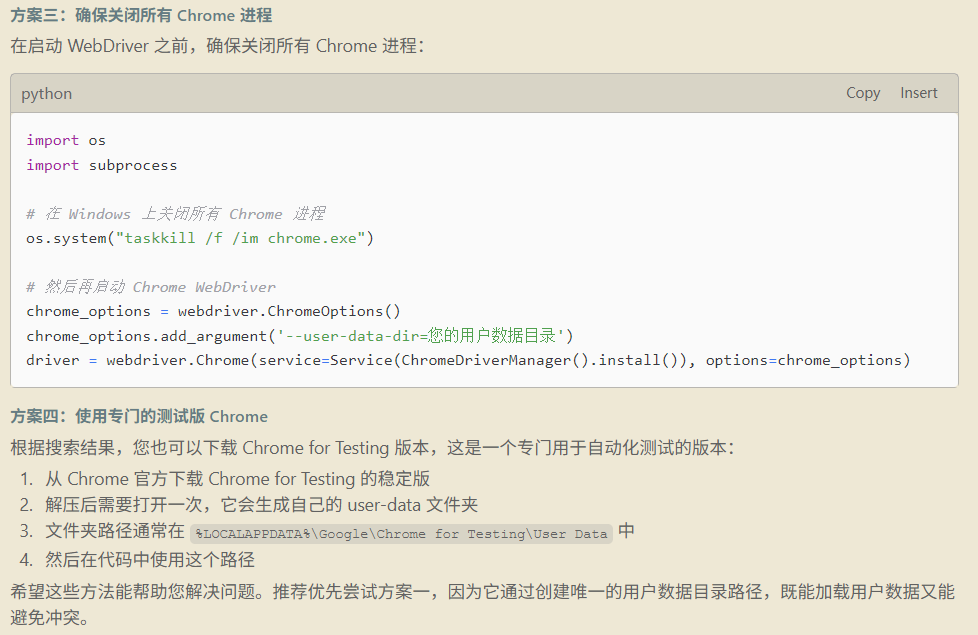
根据 AI 提示的内容,可以看到非常在努力的工作,给出推荐方案是:创建一个新的用户目录。
分析结果:
如果采用创建新用户的方案,cloudflare 验证码是通过不了的。抱着试试看的态度,准备切换浏览器,Chrome 不可以,那 Edge 是否可以呢。
4、Chrome 浏览器切换成 Edge 浏览器
1 | 由于采用chrome无法完成上述工作,请你帮我在采用相同的配置的前提下,采用edge浏览器完成上述内容。 |
Windsurf 生成内容:
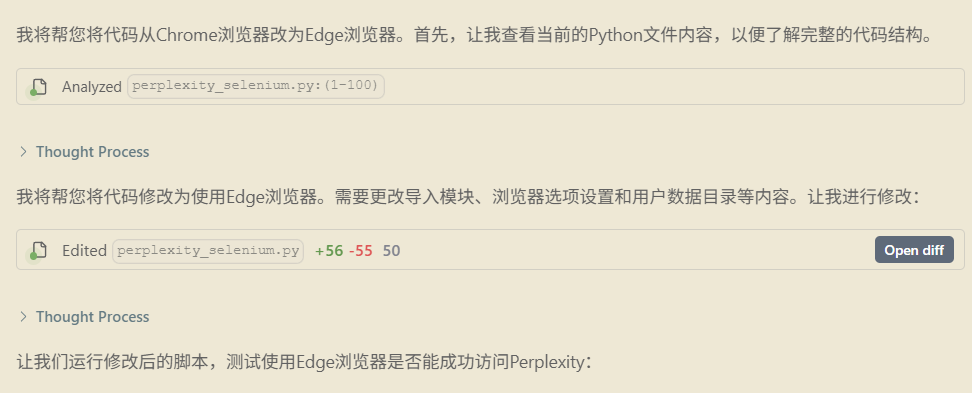
运行结果:
顺利打开 perplexity 网站,同时采用的是本机的配置文件。
5、搜索框中输入提示词进行检索功能,提示词如下:
1 | 打开perplexity以后,需要进行输入内容,然后进行检索。 |
Windsurf 生成内容:
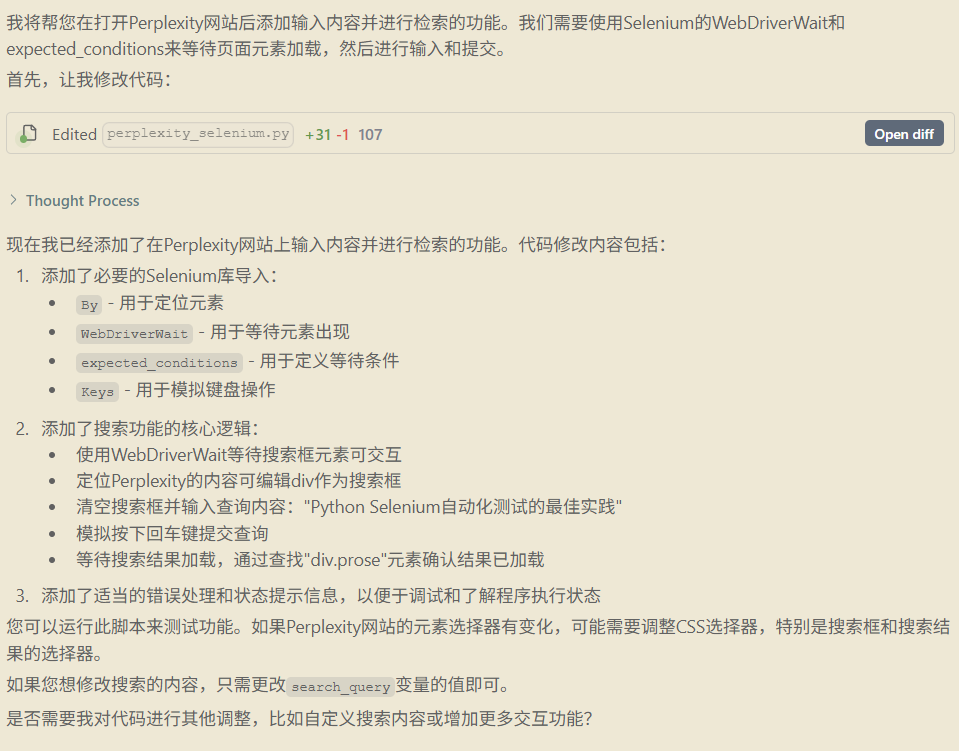
部分核心代码:
1 | # 查找搜索框 (Perplexity的主要输入框) |
运行结果:
检索框中没有任何内容。大胆猜测没有定位到检索框的位置。
6、定位到检索框,提示词如下:
1 | @perplexity_selenium.py#L108 目前输入框的前端代码是:<textarea placeholder="Ask anything…" class="overflow-auto max-h-[45vh] lg:max-h-[40vh] sm:max-h-[25vh] outline-none w-full font-sans caret-superDuper resize-none selection:bg-super/50 selection:text-textMain dark:selection:bg-superDuper/10 dark:selection:text-superDark dark:bg-offsetDark dark:text-textMainDark dark:placeholder-textOffDark placeholder:select-none bg-background text-textMain placeholder-textOff scrollbar-thumb-idle dark:scrollbar-thumb-idleDark scrollbar-thin scrollbar-track-transparent" autocomplete="off" rows="2" id="ask-input" data-1p-ignore="true" style="height: 48px !important;"></textarea>。请根据此选择合适的。 |
Windsurf 生成内容:
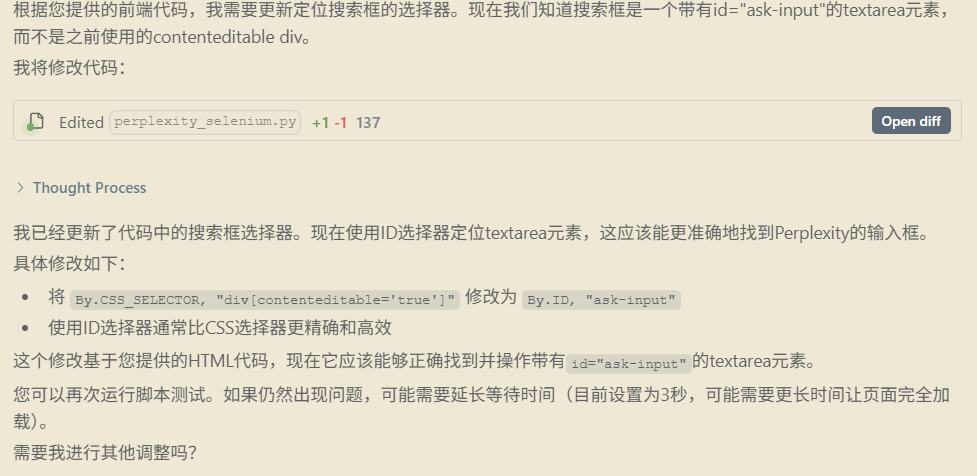
部分修改代码:
1 | search_box = wait.until(EC.element_to_be_clickable((By.ID, "ask-input"))) |
运行结果:
实现了预期效果:打开 perplexity 了并输入了检索内容,完成检索。
目前缺少的是选择模型和导出功能。
7、点击选择模型,提示词如下:
提示词的核心内容(自己实际操作选择模型的过程):
1 | @perplexity_selenium.py#L108 目前点击页面的内容是<选择模型的长条出的前端代码1>,其中我需要选择的是<选择模型第一次要点击的位置处的前端代码2>,,需要对这个位置进行点击。 |
上面的 1,2 的位置如下图所示:
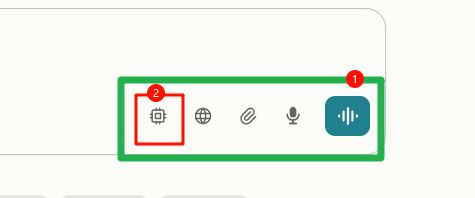
完整版内容如下,其实看上面的内容就够了。
1 |
|
Windsurf 生成内容:
运行结果:
可以弹出模型选择页面。
看完给出的修改内容:
//button[@aria-label=’Choose a model’]
感觉可能不太通用
8、点击模型的实现更加通用性,提示词如下:
1 | @perplexity_selenium.py#L111-113 这个没有通用性,如果现在不是Choose a model,还有其他的,都是不相同的。有其他的方案么 |
Windsurf 生成内容:

运行结果:
完美匹配更加普遍的方式弹出模型选择页面。
9、根据弹出的内容,选择 Claude 模型,提示词如下:
1 |
|
上面的 1,2 的位置如下图所示:
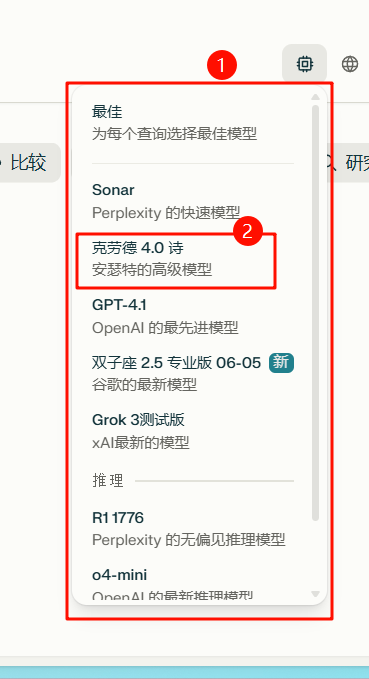
完整的内容如下:
1 |
|
Windsurf 生成内容:
运行结果:
选择 Claude 4.0 Sonnet 模型,并进行了检索。
目前仅剩导出一项功能未完成。
10、增加导出功能,提示词如下:
核心提示词:
1 |
|
完整提示词:
1 |
|
Windsurf 生成内容:
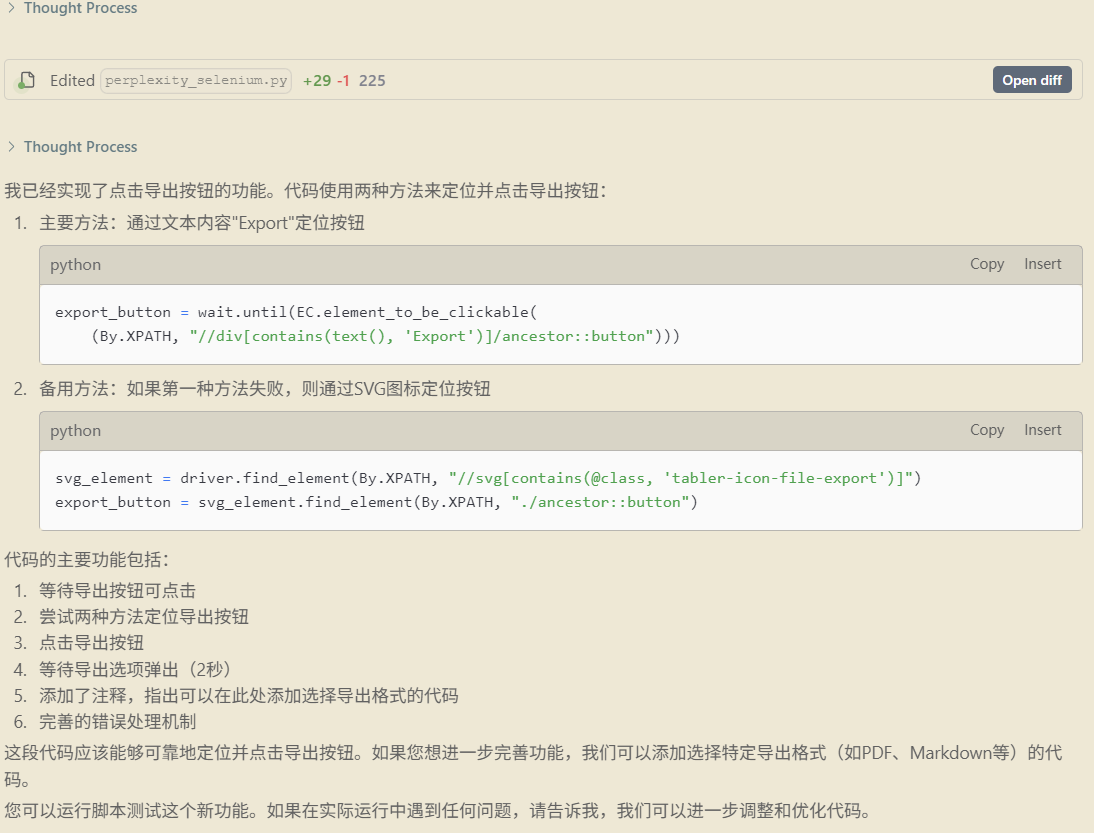
运行结果:
可以点击导出按钮,并弹出导出选项
11、点击 markdown 文件进行下载,提示词如下:
核心提示词:
1 |
|
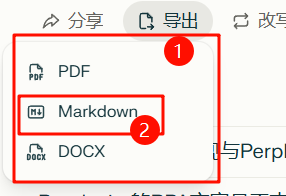
完整提示词:
1 |
|
Windsurf 生成内容:
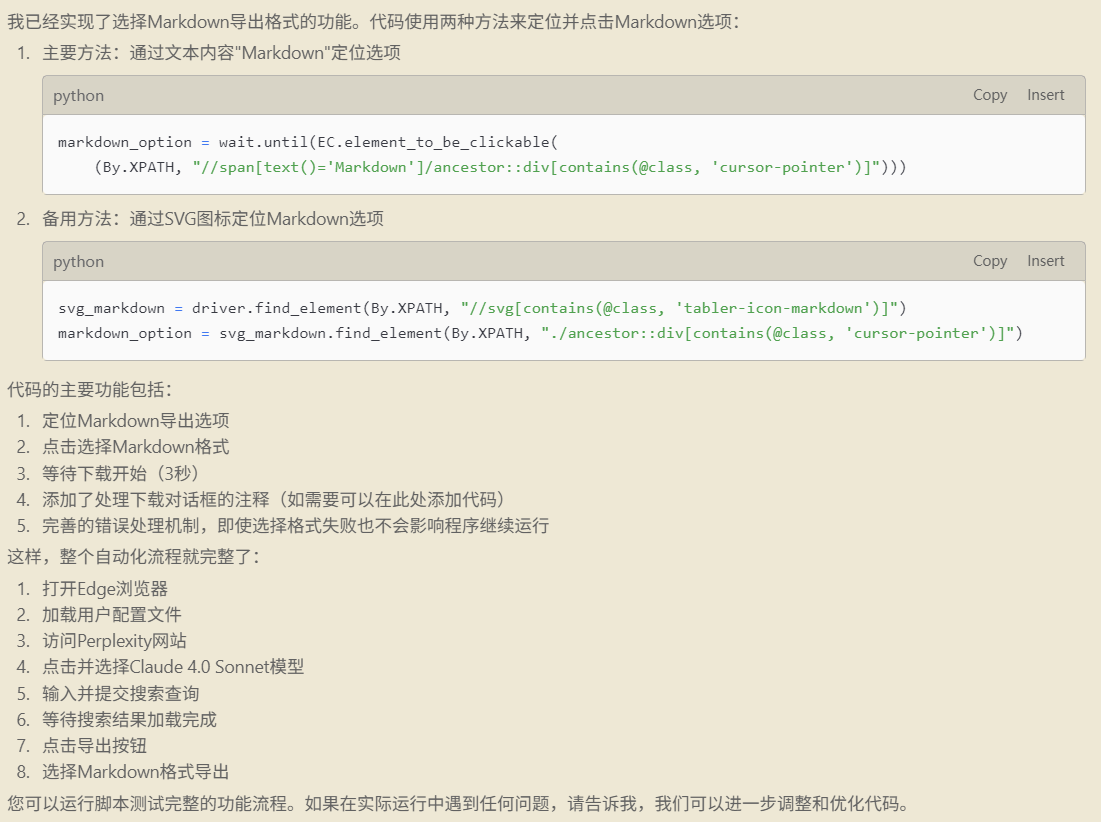
运行结果:
实现所有内容,完成内容的下载
至此,所有功能均实现。
完整代码如下:
1 | from selenium import webdriver |
温情提示:
如果出现 cloudflare 验证码不能直接跳过的情况,关闭本脚本。请使用本机的 edge 浏览器(脚本加载的用户配置文件),手动点击验证码,多次尝试打开 perplexity,均可自动跳过验证码的时候,再次使用本脚本。
edge 浏览器采用的语言是英文。